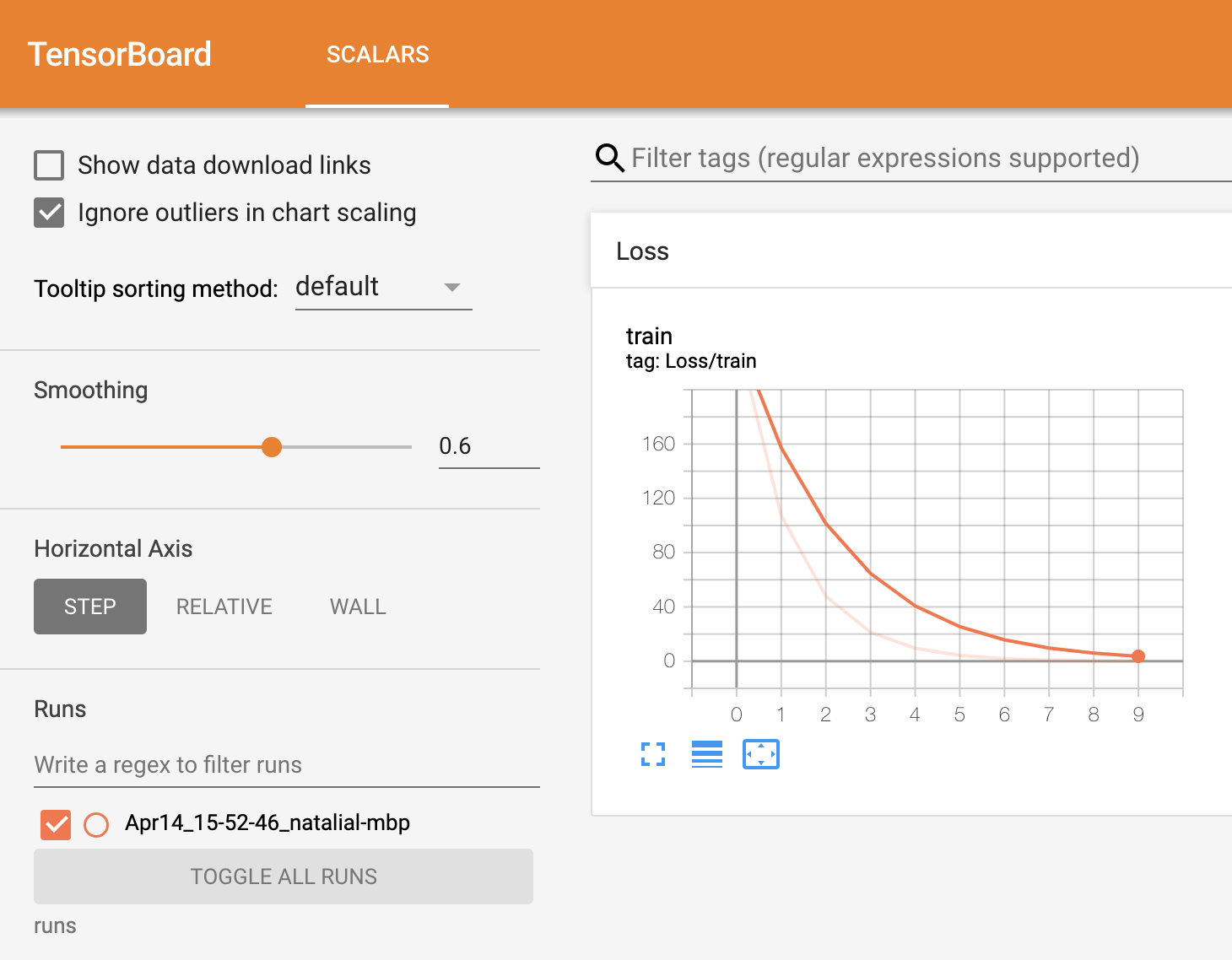
PyTorch 示例¶ 示例是具体使用特定PyTorch功能的小型、可操作示例,与我们完整的教程不同。 所有 定义神经网络 学习如何使用PyTorch的torch.nn包为MNIST数据集创建和定义神经网络。 基础 什么是 PyTorch 中的 state_dict 了解 state_dict 对象和 Python 字典如何在保存或加载 PyTorch 模型时使用。 基础知识 在PyTorch中保存和加载模型以进行推理 了解在PyTorch中保存和加载模型以进行推理的两种方法 - 通过state_dict和整个模型。 基础知识 在PyTorch中保存和加载通用检查点 为推理或恢复训练而保存和加载通用检查点模型可以帮助你在上次停止的地方继续进行。在这个示例中,我们将探讨如何保存和加载多个检查点。 基础知识 使用PyTorch在一个文件中保存和加载多个模型 在本教程中,学习如何保存和加载多个模型可以帮助您重复使用之前训练过的模型。 基础知识 使用PyTorch从不同模型加载参数进行预热启动模型 了解如何通过部分加载模型或加载部分模型来预热启动训练过程,可以帮助您的模型比从头开始训练更快地收敛。 基础知识 在PyTorch中跨设备保存和加载模型 了解如何使用PyTorch相对简单地在不同设备(CPU和GPU)之间保存和加载模型。 基础知识 在PyTorch中将梯度归零 了解何时应该将梯度归零以及这样做如何帮助提高模型的准确性。 基础知识 PyTorch 基准测试 学习如何使用 PyTorch 的基准测试模块来测量和比较代码的性能 基础 PyTorch 基准测试(快速入门) 学习如何测量代码片段运行时间并收集指令。 基础知识 PyTorch 分析器 了解如何使用 PyTorch 的分析器来测量操作符的时间和内存消耗 基础 支持仪器化和跟踪技术API (ITT API) 的 PyTorch 分析器 了解如何使用支持仪器化和跟踪技术API (ITT API) 的 PyTorch 分析器,在 Intel® VTune™ Profiler GUI 中可视化操作符标签 基础知识 使用torch.compile IPEX后端 了解如何使用torch.compile IPEX后端 基础 在PyTorch中推理形状 学习如何使用元设备来推理模型中的形状。 基础 从检查点加载 nn.Module 的提示 了解从检查点加载 nn.Module 的提示。 基础知识 (测试版)使用 TORCH_LOGS 观察 torch.compile 了解如何使用 torch 日志记录 API 来观察编译过程。 基础知识 nn.Module 中用于加载 state_dict 和张量子类的扩展点 nn.Module 中的新扩展点。 基础 torch.export AOTInductor 教程(适用于 Python 运行时) 学习如何使用 AOTInductor 为 Python 运行时提供端到端的示例。 基础知识 使用Captum进行模型可解释性 学习如何使用Captum将图像分类器的预测归因于其相应的图像特征,并可视化归因结果。 可解释性,Captum 如何在PyTorch中使用TensorBoard 学习如何在PyTorch中使用TensorBoard,以及如何在TensorBoard UI中可视化数据 可视化,TensorBoard 动态量化 将动态量化应用于简单的LSTM模型。 量化,文本,模型优化 用于部署的TorchScript 了解如何将训练好的模型导出为TorchScript格式,以及如何在C++中加载TorchScript模型并进行推理。 TorchScript 使用Flask进行部署 学习如何使用Flask(一个轻量级的Web服务器)快速从训练好的PyTorch模型设置一个Web API。 生产环境,TorchScript PyTorch 移动性能优化指南 在移动设备(Android 和 iOS)上使用 PyTorch 的性能优化指南列表。 移动设备, 模型优化 使用PyTorch Android预构建库制作Android原生应用程序 学习如何从头开始制作使用LibTorch C++ API并使用带有自定义C++操作符的TorchScript模型的Android应用程序。 移动设备 融合模块的配方 学习如何将一系列 PyTorch 模块融合为一个模块,以在量化之前减少模型大小。 移动设备 移动端量化配方 学习如何在不显著降低精度的情况下减少模型大小并加快运行速度。 移动端,量化 脚本编写和移动端优化 学习如何将模型转换为TorchScript,并(可选)针对移动应用进行优化。 移动端 为iOS准备模型的教程 学习如何在iOS项目中添加模型并使用PyTorch pod进行iOS开发。 移动设备 Android 模型准备示例 学习如何在 Android 项目中添加模型并使用 PyTorch 库进行 Android 开发。 移动设备 在 Android 和 iOS 中的移动解释器工作流程 了解如何在 iOS 和 Android 设备上使用移动解释器。 移动 剖析基于PyTorch RPC的工作负载 如何使用PyTorch分析器来剖析基于RPC的工作负载。 生产环境 自动混合精度 使用 torch.cuda.amp 在 NVIDIA GPU 上减少运行时间和节省内存。 模型优化 性能调优指南 实现最佳性能的提示。 模型优化 使用 run_cpu 脚本在 Intel® Xeon® 上优化 CPU 性能 如何使用 run_cpu 脚本在 Intel® Xeon CPU 上实现最佳运行时配置。 模型优化 在 AWS Graviton 处理器上进行 PyTorch 推理性能调优 在 AWS Graviton CPU 上实现最佳推理性能的提示 模型优化 利用英特尔® 高级矩阵扩展 学习如何利用英特尔® 高级矩阵扩展。 模型优化 (测试版)使用 torch.compile 编译优化器 使用 torch.compile 加速优化器 模型优化 (测试版)使用学习率调度器运行编译后的优化器 使用LRScheduler和torch.compiled优化器加速训练 模型优化 使用用户定义的 Triton 内核与 ``torch.compile`` 学习如何使用用户定义的内核与 ``torch.compile`` 模型优化 ``torch.compile`` 中的编译时缓存 了解如何在 ``torch.compile`` 中配置编译时缓存 模型优化 通过区域编译减少 torch.compile 的冷启动编译时间 了解如何使用区域编译来控制冷启动编译时间 模型优化 英特尔® 扩展 for PyTorch* 英特尔® 扩展 for PyTorch* 简介 模型优化 英特尔® 神经压缩器用于 PyTorch 使用英特尔® 神经压缩器轻松实现 PyTorch 量化。 量化,模型优化 开始使用 DeviceMesh 学习如何使用 DeviceMesh 分布式训练 使用ZeroRedundancyOptimizer共享优化器状态 如何使用ZeroRedundancyOptimizer减少内存消耗。 分布式训练 使用 TensorPipe RPC 进行直接设备到设备的通信 如何使用直接 GPU 到 GPU 通信的 RPC。 分布式训练 支持TorchScript的分布式优化器 如何为分布式优化器启用TorchScript支持。 分布式训练,TorchScript 分布式检查点 (DCP) 入门 学习如何使用分布式检查点包来检查分布式模型。 分布式训练 异步检查点(DCP) 了解如何使用分布式检查点包对分布式模型进行检查点操作。 分布式训练 开始使用 CommDebugMode 了解如何为 DTensors 使用 CommDebugMode 分布式训练 将PyTorch Stable Diffusion模型部署为Vertex AI端点 了解如何使用TorchServe在Vertex AI中部署模型 生产环境