torchaudio.transforms¶
Transforms 是常见的音频变换。它们可以使用 torch.nn.Sequential 链接在一起
实用工具¶
AmplitudeToDB¶
-
class
torchaudio.transforms.AmplitudeToDB(stype: str = 'power', top_db: Optional[float] = None)[source]¶ 将张量从功率/幅度尺度转换为分贝尺度。


此输出取决于输入张量中的最大值,因此对于分割成片段与完整片段的音频剪辑,可能会返回不同的值。
- Parameters
-
forward(x: torch.Tensor) → torch.Tensor[source]¶ 来自 Librosa 的数值稳定实现。
https://librosa.org/doc/latest/generated/librosa.amplitude_to_db.html
- Parameters
x (Tensor) – 转换为分贝刻度之前的输入张量。
- Returns
以分贝刻度输出的张量。
- Return type
张量
MelScale¶
-
class
torchaudio.transforms.MelScale(n_mels: int = 128, sample_rate: int = 16000, f_min: float = 0.0, f_max: Optional[float] = None, n_stft: int = 201, norm: Optional[str] = None, mel_scale: str = 'htk')[source]¶ 将普通 STFT 转换为使用三角形滤波器组的梅尔频率 STFT。
- Parameters
n_mels (int, optional) – 梅尔滤波器组的数量。(默认值:
128)sample_rate (int, optional) – 音频信号的采样率。(默认值:
16000)f_min (float, optional) – 最小频率。(默认值:
0.)n_stft (int, 可选) – STFT中的频谱分箱数量。参见
n_fft在Spectrogram. (默认:201)norm (str 或 None, 可选) – 如果为
'slaney',则将三角梅尔权重除以梅尔频带的宽度(面积归一化)。(默认值:None)mel_scale (str, optional) – 要使用的比例:
htk或slaney。(默认值:htk)
另请参见
torchaudio.functional.melscale_fbanks()- 用于生成滤波器组的函数。-
forward(specgram: torch.Tensor) → torch.Tensor[source]¶ - Parameters
specgram (Tensor) – 维度为 (…, freq, time) 的频谱图 STFT。
- Returns
大小为 (…,
n_mels, time) 的梅尔频率语谱图。- Return type
张量
InverseMelScale¶
-
class
torchaudio.transforms.InverseMelScale(n_stft: int, n_mels: int = 128, sample_rate: int = 16000, f_min: float = 0.0, f_max: Optional[float] = None, max_iter: int = 100000, tolerance_loss: float = 1e-05, tolerance_change: float = 1e-08, sgdargs: Optional[dict] = None, norm: Optional[str] = None, mel_scale: str = 'htk')[source]¶ 从梅尔频率域估计正常频率域的短时傅里叶变换(STFT)。
它使用 SGD 最小化输入梅尔频谱图与估计频谱图和滤波器组乘积之间的欧几里得范数。
- Parameters
n_stft (int) – STFT 中的频带数量。参见
n_fft在Spectrogram。n_mels (int, optional) – 梅尔滤波器组的数量。(默认值:
128)sample_rate (int, optional) – 音频信号的采样率。(默认值:
16000)f_min (float, optional) – 最小频率。(默认值:
0.)max_iter (int, optional) – 优化迭代的最大次数。(默认值:
100000)tolerance_loss (float, optional) – 停止优化时的损失值。(默认:
1e-5)tolerance_change (float, optional) – 停止优化时的损失差异。(默认值:
1e-8)norm (str 或 None, 可选) – 如果为 'slaney',则将三角梅尔权重除以梅尔频带的宽度(面积归一化)。(默认值:
None)mel_scale (str, optional) – 要使用的比例:
htk或slaney。(默认值:htk)
-
forward(melspec: torch.Tensor) → torch.Tensor[source]¶ - Parameters
melspec (Tensor) – 维度为 (…,
n_mels, time) 的梅尔频率谱图- Returns
大小为 (…, freq, time) 的线性尺度频谱图
- Return type
张量
MuLawEncoding¶
-
class
torchaudio.transforms.MuLawEncoding(quantization_channels: int = 256)[source]¶ 基于 μ 律压扩对信号进行编码。

有关更多信息,请参见 维基百科条目
该算法假设信号已缩放到 -1 到 1 之间,并返回一个编码值在 0 到 quantization_channels - 1 范围内的信号。
- Parameters
quantization_channels (int, optional) – 通道数量。(默认值:
256)
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = torchaudio.transforms.MuLawEncoding(quantization_channels=512) >>> mulawtrans = transform(waveform)
-
forward(x: torch.Tensor) → torch.Tensor[source]¶ - Parameters
x (Tensor) – 要编码的信号。
- Returns
编码信号。
- Return type
张量
MuLawDecoding¶
-
class
torchaudio.transforms.MuLawDecoding(quantization_channels: int = 256)[source]¶ 解码 μ 律编码信号。
有关更多信息,请参见 维基百科条目
这期望一个值在 0 和
quantization_channels - 1之间的输入,并返回一个缩放至 -1 到 1 之间的信号。- Parameters
quantization_channels (int, optional) – 通道数量。(默认值:
256)
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = torchaudio.transforms.MuLawDecoding(quantization_channels=512) >>> mulawtrans = transform(waveform)
-
forward(x_mu: torch.Tensor) → torch.Tensor[source]¶ - Parameters
x_mu (Tensor) – 需要解码的 mu-law 编码信号。
- Returns
信号已解码。
- Return type
张量
重采样¶
-
class
torchaudio.transforms.Resample(orig_freq: int = 16000, new_freq: int = 16000, resampling_method: str = 'sinc_interpolation', lowpass_filter_width: int = 6, rolloff: float = 0.99, beta: Optional[float] = None, *, dtype: Optional[torch.dtype] = None)[source]¶ 将信号从一个频率重采样到另一个频率。可以指定一种重采样方法。
注意
如果对精度高于 float32 的波形进行重采样,可能会出现轻微的精度损失,因为内核仅以 float32 格式缓存一次。如果您的应用对高精度重采样至关重要,函数形式将保留更高的精度,但由于不缓存内核,运行速度会较慢。或者,您可以重写一个变换来缓存更高精度的内核。
- Parameters
orig_freq (int, optional) – 信号的原始频率。(默认值:
16000)new_freq (int, optional) – 期望的频率。(默认值:
16000)resampling_method (str, optional) – 要使用的重采样方法。 选项:[
sinc_interpolation,kaiser_window](默认值:'sinc_interpolation')lowpass_filter_width (int, optional) – 控制滤波器的锐度,值越大越锐利但效率越低。(默认值:
6)rolloff (float, optional) – 滤波器的滚降频率,表示为奈奎斯特频率的分数。 较低的值会减少抗混叠效果,但也会降低部分最高频率。(默认值:
0.99)dtype (torch.device, optional) – 确定重采样核的预计算和缓存精度。如果未提供,则使用
torch.float64计算核并缓存为torch.float32。如果需要更高的精度,请提供torch.float64,此时预计算的核将作为torch.float64进行计算和缓存。如果您需要使用较低精度的 resample,请不要提供此参数,而是使用Resample.to(dtype),以便核生成仍在torch.float64上执行。
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = transforms.Resample(sample_rate, sample_rate/10) >>> waveform = transform(waveform)
- Tutorials using
Resample:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
维度为 (…, time) 的输出信号。
- Return type
张量

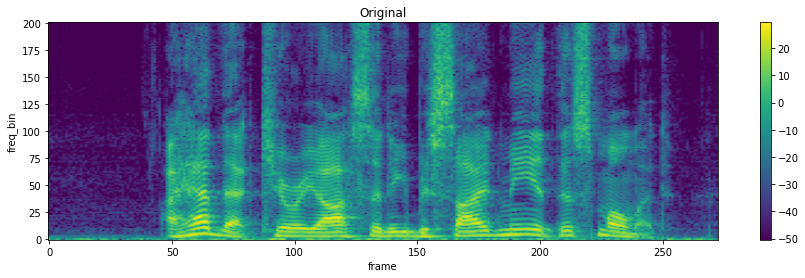
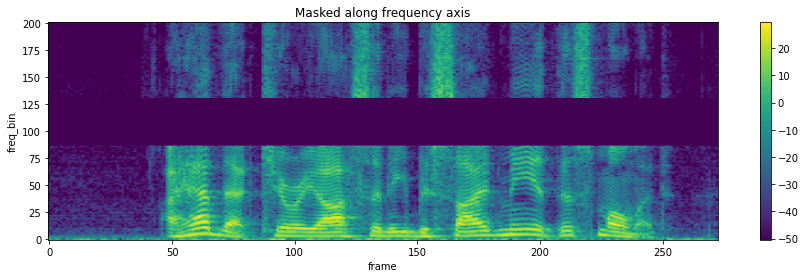
FrequencyMasking¶
-
class
torchaudio.transforms.FrequencyMasking(freq_mask_param: int, iid_masks: bool = False)[source]¶ 在频域中对频谱图应用掩码。
在 SpecAugment 中提出 [1]。
- Parameters
- Example
>>> spectrogram = torchaudio.transforms.Spectrogram() >>> masking = torchaudio.transforms.FrequencyMasking(freq_mask_param=80) >>> >>> original = spectrogram(waveform) >>> masked = masking(original)
- Tutorials using
FrequencyMasking:
-
forward(specgram: torch.Tensor, mask_value: float = 0.0) → torch.Tensor¶ - Parameters
specgram (Tensor) – 维度为 (…, freq, time) 的张量。
mask_value (float) – 要分配给被屏蔽列的值。
- Returns
维度为 (…, freq, time) 的掩码频谱图。
- Return type
张量
TimeMasking¶
-
class
torchaudio.transforms.TimeMasking(time_mask_param: int, iid_masks: bool = False, p: float = 1.0)[source]¶ 在时域中对频谱图应用掩码。
在 SpecAugment 中提出 [1]。
- Parameters
- Example
>>> spectrogram = torchaudio.transforms.Spectrogram() >>> masking = torchaudio.transforms.TimeMasking(time_mask_param=80) >>> >>> original = spectrogram(waveform) >>> masked = masking(original)
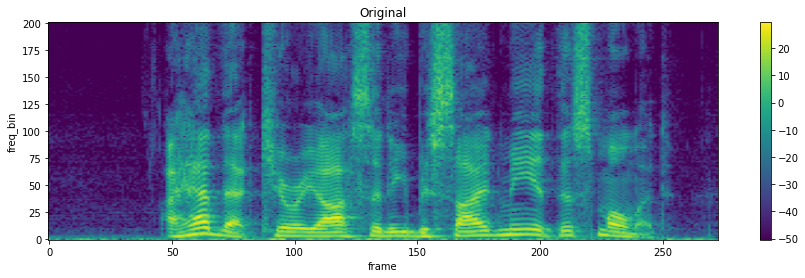
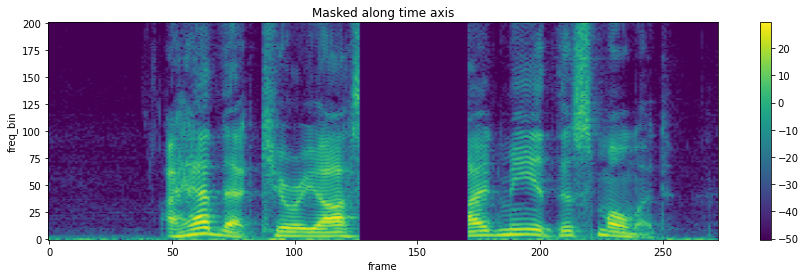
- Tutorials using
TimeMasking:
-
forward(specgram: torch.Tensor, mask_value: float = 0.0) → torch.Tensor¶ - Parameters
specgram (Tensor) – 维度为 (…, freq, time) 的张量。
mask_value (float) – 要分配给被屏蔽列的值。
- Returns
维度为 (…, freq, time) 的掩码频谱图。
- Return type
张量
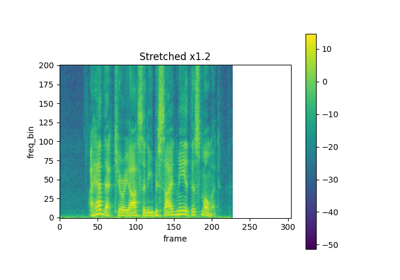
TimeStretch¶
-
class
torchaudio.transforms.TimeStretch(hop_length: Optional[int] = None, n_freq: int = 201, fixed_rate: Optional[float] = None)[source]¶ 在给定速率下,沿时间轴拉伸 STFT 而不改变音高。
在 SpecAugment 中提出 [1]。
- Parameters
- Example
>>> spectrogram = torchaudio.transforms.Spectrogram() >>> stretch = torchaudio.transforms.TimeStretch() >>> >>> original = spectrogram(waveform) >>> streched_1_2 = stretch(original, 1.2) >>> streched_0_9 = stretch(original, 0.9)
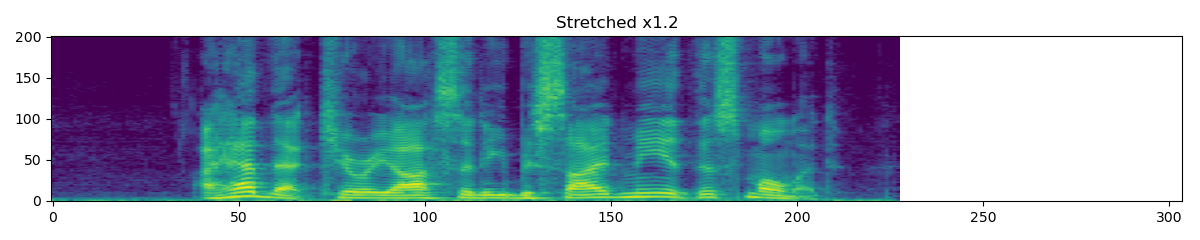
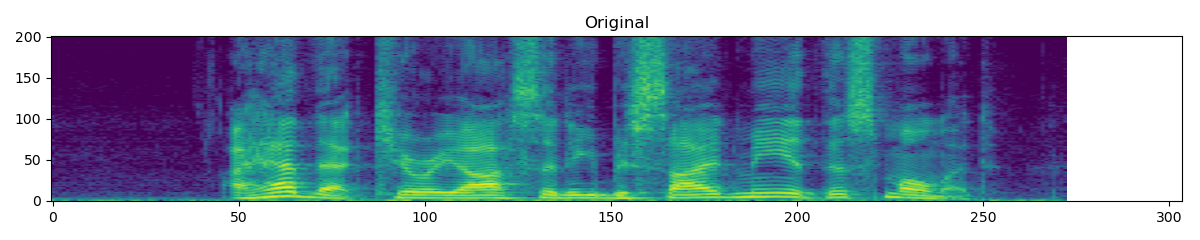
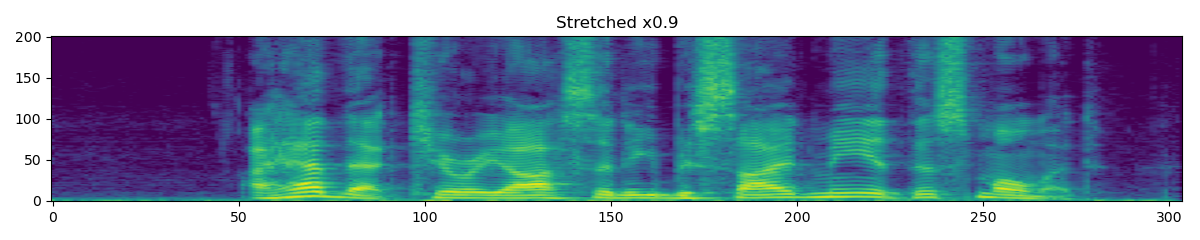
- Tutorials using
TimeStretch:
-
forward(complex_specgrams: torch.Tensor, overriding_rate: Optional[float] = None) → torch.Tensor[source]¶
淡出¶
-
class
torchaudio.transforms.Fade(fade_in_len: int = 0, fade_out_len: int = 0, fade_shape: str = 'linear')[source]¶ 为波形添加淡入和/或淡出效果。
- Parameters
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = transforms.Fade(fade_in_len=sample_rate, fade_out_len=2 * sample_rate, fade_shape='linear') >>> faded_waveform = transform(waveform)
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
维度为 (…, time) 的音频张量。
- Return type
张量
卷¶
-
class
torchaudio.transforms.Vol(gain: float, gain_type: str = 'amplitude')[source]¶ 为波形添加音量。
- Parameters
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
维度为 (…, time) 的音频张量。
- Return type
张量
特征提取¶
频谱图¶
-
class
torchaudio.transforms.Spectrogram(n_fft: int = 400, win_length: Optional[int] = None, hop_length: Optional[int] = None, pad: int = 0, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, power: Optional[float] = 2.0, normalized: bool = False, wkwargs: Optional[dict] = None, center: bool = True, pad_mode: str = 'reflect', onesided: bool = True, return_complex: Optional[bool] = None)[source]¶ 从音频信号创建频谱图。
- Parameters
n_fft (int, optional) – FFT 的大小,创建
n_fft // 2 + 1个频带。(默认值:400)hop_length (int 或 None, 可选) – STFT 窗口之间的跳跃长度。(默认值:
win_length // 2)pad (int, optional) – 信号的双边填充。(默认值:
0)window_fn (Callable[.., Tensor], optional) – 一个用于创建窗口张量的函数,该函数将应用于/乘以每个帧/窗口。(默认值:
torch.hann_window)power (float 或 None, 可选) – 幅度谱图的指数, (必须 > 0),例如:1 表示能量,2 表示功率等。 如果为 None,则返回复数频谱。(默认值:
2)normalized (bool, optional) – 是否在 stft 后按幅度进行归一化。(默认值:
False)center (bool, optional) – 是否在两侧填充
waveform,以便第 \(t\) 帧位于时间 \(t \times \text{hop\_length}\) 的中心。 (默认值:True)pad_mode (string, optional) – 控制当
center为True时使用的填充方法。(默认值:"reflect")onesided (bool, optional) – 控制是否返回一半的结果以避免冗余(默认值:
True)return_complex (bool, optional) – 已弃用且未使用。
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = torchaudio.transforms.Spectrogram(n_fft=800) >>> spectrogram = transform(waveform)
- Tutorials using
Spectrogram:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
维度 (…, freq, time),其中 freq 是
n_fft // 2 + 1,而n_fft是傅里叶分箱的数量,time 是窗口跳数的数量(n_frame)。- Return type
张量
InverseSpectrogram¶
-
class
torchaudio.transforms.InverseSpectrogram(n_fft: int = 400, win_length: Optional[int] = None, hop_length: Optional[int] = None, pad: int = 0, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, normalized: bool = False, wkwargs: Optional[dict] = None, center: bool = True, pad_mode: str = 'reflect', onesided: bool = True)[source]¶ 创建逆频谱图,从频谱图中恢复音频信号。
- Parameters
n_fft (int, optional) – FFT 的大小,创建
n_fft // 2 + 1个频带。(默认值:400)hop_length (int 或 None, 可选) – STFT 窗口之间的跳跃长度。(默认值:
win_length // 2)pad (int, optional) – 信号的双边填充。(默认值:
0)window_fn (Callable[.., Tensor], optional) – 一个用于创建窗口张量的函数,该函数将应用于/乘以每个帧/窗口。(默认值:
torch.hann_window)normalized (bool, optional) – 是否在 stft 后对频谱图进行幅度归一化。 (默认值:
False)center (bool, optional) – 是否对频谱图中的信号在两侧进行填充,使得第 \(t\) 帧的中心位于时间 \(t \times \text{hop\_length}\)。 (默认值:
True)pad_mode (string, optional) – 控制当
center为True时使用的填充方法。(默认值:"reflect")onesided (bool, optional) – 控制是否使用频谱图返回一半的结果以避免冗余(默认值:
True)
- Example
>>> batch, freq, time = 2, 257, 100 >>> length = 25344 >>> spectrogram = torch.randn(batch, freq, time, dtype=torch.cdouble) >>> transform = transforms.InverseSpectrogram(n_fft=512) >>> waveform = transform(spectrogram, length)
- Tutorials using
InverseSpectrogram:
-
forward(spectrogram: torch.Tensor, length: Optional[int] = None) → torch.Tensor[source]¶
MelSpectrogram¶
-
class
torchaudio.transforms.MelSpectrogram(sample_rate: int = 16000, n_fft: int = 400, win_length: Optional[int] = None, hop_length: Optional[int] = None, f_min: float = 0.0, f_max: Optional[float] = None, pad: int = 0, n_mels: int = 128, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, power: float = 2.0, normalized: bool = False, wkwargs: Optional[dict] = None, center: bool = True, pad_mode: str = 'reflect', onesided: bool = True, norm: Optional[str] = None, mel_scale: str = 'htk')[source]¶ 为原始音频信号创建梅尔频谱图。
这是
torchaudio.transforms.Spectrogram()和 以及torchaudio.transforms.MelScale()的组合。- Sources
- Parameters
sample_rate (int, optional) – 音频信号的采样率。(默认值:
16000)n_fft (int, optional) – FFT 的大小,创建
n_fft // 2 + 1个频带。(默认值:400)hop_length (int 或 None, 可选) – STFT 窗口之间的跳跃长度。(默认值:
win_length // 2)f_min (float, optional) – 最小频率。(默认值:
0.)pad (int, optional) – 信号的双边填充。(默认值:
0)n_mels (int, optional) – 梅尔滤波器组的数量。(默认值:
128)window_fn (Callable[.., Tensor], optional) – 一个用于创建窗口张量的函数,该函数将应用于/乘以每个帧/窗口。(默认值:
torch.hann_window)power (float, optional) – 幅度谱的指数, (必须 > 0),例如:1 表示能量,2 表示功率等。(默认值:
2)normalized (bool, optional) – 是否在 stft 后按幅度进行归一化。(默认值:
False)wkwargs (Dict[.., ..] 或 None,可选) – 窗口函数的参数。(默认值:
None)center (bool, optional) – 是否在两侧填充
waveform,以便第 \(t\) 帧位于时间 \(t \times \text{hop\_length}\) 的中心。 (默认值:True)pad_mode (string, optional) – 控制当
center为True时使用的填充方法。(默认值:"reflect")onesided (bool, optional) – 控制是否返回一半的结果以避免冗余。(默认值:
True)norm (str 或 None, 可选) – 如果为 'slaney',则将三角梅尔权重除以梅尔频带的宽度(面积归一化)。(默认值:
None)mel_scale (str, optional) – 要使用的比例:
htk或slaney。(默认值:htk)
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = transforms.MelSpectrogram(sample_rate) >>> mel_specgram = transform(waveform) # (channel, n_mels, time)
另请参见
torchaudio.functional.melscale_fbanks()- 用于生成滤波器组的函数。- Tutorials using
MelSpectrogram:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
大小为 (…,
n_mels, time) 的梅尔频率语谱图。- Return type
张量
GriffinLim¶
-
class
torchaudio.transforms.GriffinLim(n_fft: int = 400, n_iter: int = 32, win_length: Optional[int] = None, hop_length: Optional[int] = None, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, power: float = 2.0, wkwargs: Optional[dict] = None, momentum: float = 0.99, length: Optional[int] = None, rand_init: bool = True)[source]¶ 使用 Griffin-Lim 变换从线性尺度幅度谱图计算波形。
实现移植自 librosa [2]、A fast Griffin-Lim algorithm [3] 以及 Signal estimation from modified short-time Fourier transform [4]。
- Parameters
n_fft (int, optional) – FFT 的大小,创建
n_fft // 2 + 1个频带。(默认值:400)n_iter (int, optional) – 相位恢复过程的迭代次数。(默认值:
32)hop_length (int 或 None, 可选) – STFT 窗口之间的跳跃长度。(默认值:
win_length // 2)window_fn (Callable[.., Tensor], optional) – 一个用于创建窗口张量的函数,该函数将应用于/乘以每个帧/窗口。(默认值:
torch.hann_window)power (float, optional) – 幅度谱的指数, (必须 > 0),例如:1 表示能量,2 表示功率等。(默认值:
2)momentum (float, optional) – 快速 Griffin-Lim 的动量参数。 将其设置为 0 可恢复原始的 Griffin-Lim 方法。 接近 1 的值可以导致更快的收敛,但大于 1 可能无法收敛。(默认值:
0.99)length (int, optional) – 预期输出的数组长度。(默认值:
None)rand_init (bool, optional) – 如果为 True,则随机初始化相位;否则初始化为零。(默认值:
True)
- Example
>>> batch, freq, time = 2, 257, 100 >>> spectrogram = torch.randn(batch, freq, time) >>> transform = transforms.GriffinLim(n_fft=512) >>> waveform = transform(spectrogram)
- Tutorials using
GriffinLim:
-
forward(specgram: torch.Tensor) → torch.Tensor[source]¶ - Parameters
specgram (Tensor) – 维度为 (…, freq, frames) 的仅包含幅度的 STFT 频谱图,其中 freq 为
n_fft // 2 + 1。- Returns
(…, time) 的波形,其中 time 等于给定的
length参数。- Return type
张量
MFCC¶
-
class
torchaudio.transforms.MFCC(sample_rate: int = 16000, n_mfcc: int = 40, dct_type: int = 2, norm: str = 'ortho', log_mels: bool = False, melkwargs: Optional[dict] = None)[source]¶ 从音频信号创建梅尔频率倒谱系数。
默认情况下,此函数会在以分贝缩放的梅尔频谱上计算 MFCC。 这并非教科书式的实现,但在此处采用该方式是为了与 librosa 保持一致。
该输出取决于输入频谱图中的最大值,因此对于分割成片段与完整音频剪辑的同一音频,可能会返回不同的值。
- Parameters
另请参见
torchaudio.functional.melscale_fbanks()- 用于生成滤波器组的函数。- Tutorials using
MFCC:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
大小为 (…,
n_mfcc, time) 的 specgram_mel_db。- Return type
张量
LFCC¶
-
class
torchaudio.transforms.LFCC(sample_rate: int = 16000, n_filter: int = 128, f_min: float = 0.0, f_max: Optional[float] = None, n_lfcc: int = 40, dct_type: int = 2, norm: str = 'ortho', log_lf: bool = False, speckwargs: Optional[dict] = None)[source]¶ 从音频信号创建线性频率倒谱系数。
默认情况下,此函数会在对数分贝缩放的线性滤波频谱图上计算 LFCC。 这并非教科书式的实现,但在此处采用该方式是为了与 librosa 保持一致。
该输出取决于输入频谱图中的最大值,因此对于分割成片段与完整音频剪辑的同一音频,可能会返回不同的值。
- Parameters
sample_rate (int, optional) – 音频信号的采样率。(默认值:
16000)n_filter (int, optional) – 要应用的线性滤波器数量。(默认值:
128)n_lfcc (int, optional) – 要保留的 lfc 系数数量。(默认值:
40)f_min (float, optional) – 最小频率。(默认值:
0.)dct_type (int, optional) – 要使用的 DCT(离散余弦变换)类型。(默认值:
2)norm (str, optional) – 要使用的范数。(默认值:
'ortho')log_lf (bool, optional) – 是否使用对数线性频率(log-lf)频谱图代替分贝缩放(db-scaled)。(默认值:
False)
另请参见
torchaudio.functional.linear_fbanks()- 用于生成滤波器组的函数。- Tutorials using
LFCC:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
大小为 (…,
n_lfcc, time) 的线性频率倒谱系数。- Return type
张量
ComputeDeltas¶
-
class
torchaudio.transforms.ComputeDeltas(win_length: int = 5, mode: str = 'replicate')[source]¶ 计算张量(通常是频谱图)的 delta 系数。
参见 torchaudio.functional.compute_deltas 以获取更多详情。
- Parameters
-
forward(specgram: torch.Tensor) → torch.Tensor[source]¶ - Parameters
specgram (Tensor) – 维度为 (…, freq, time) 的音频张量。
- Returns
维度为 (…, freq, time) 的增量张量。
- Return type
张量
PitchShift¶
-
class
torchaudio.transforms.PitchShift(sample_rate: int, n_steps: int, bins_per_octave: int = 12, n_fft: int = 512, win_length: Optional[int] = None, hop_length: Optional[int] = None, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, wkwargs: Optional[dict] = None)[source]¶ 将波形的音高移动
n_steps个步骤。
- Parameters
waveform (Tensor) – 形状为 (…, time) 的输入波形。
sample_rate (int) – waveform的采样率。
n_steps (int) – 用于偏移 waveform 的(分数)步数。
bins_per_octave (int, optional) – 每个八度的步数(默认值:
12)。n_fft (int, optional) – FFT 大小,创建
n_fft // 2 + 1个频带(默认值:512)。win_length (int 或 None, 可选) – 窗口大小。如果为 None,则使用
n_fft。(默认值:None)。hop_length (int 或 None,可选) – STFT 窗口之间的跳跃长度。如果为 None,则使用
win_length // 4(默认值:None)。window (Tensor 或 None, 可选) – 应用于/乘以每个帧/窗口的窗口张量。 如果为 None,则使用
torch.hann_window(win_length)(默认值:None)。
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = transforms.PitchShift(sample_rate, 4) >>> waveform_shift = transform(waveform) # (channel, time)
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
形状为 (…, time) 的移调音频。
- Return type
张量
SlidingWindowCmn¶
-
class
torchaudio.transforms.SlidingWindowCmn(cmn_window: int = 600, min_cmn_window: int = 100, center: bool = False, norm_vars: bool = False)[source]¶ 对每个语音片段应用滑动窗口倒谱均值(以及可选的方差)归一化。
- Parameters
cmn_window (int, optional) – 用于计算运行平均CMN的帧数窗口(int,默认值 = 600)
min_cmn_window (int, optional) – 解码开始时使用的最小 CMN 窗口(仅在开始时增加延迟)。 仅当 center == false 时适用,如果 center==true 则被忽略(int,默认值 = 100)
center (bool, optional) – 如果为 true,则使用以当前帧为中心的窗口(在可能的情况下,模去端点效应)。如果为 false,则窗口位于左侧。(bool,默认值 = false)
norm_vars (bool, optional) – 如果为 true,则将方差归一化为 1。(bool,默认值 = false)
-
forward(specgram: torch.Tensor) → torch.Tensor[source]¶ - Parameters
specgram (Tensor) – 维度为 (…, time, freq) 的语谱图张量。
- Returns
维度为 (…, time, freq) 的频谱张量。
- Return type
张量
SpectralCentroid¶
-
class
torchaudio.transforms.SpectralCentroid(sample_rate: int, n_fft: int = 400, win_length: Optional[int] = None, hop_length: Optional[int] = None, pad: int = 0, window_fn: Callable[[...], torch.Tensor] = <built-in method hann_window of type object>, wkwargs: Optional[dict] = None)[source]¶ 沿时间轴计算每个通道的频谱质心。
频谱质心定义为频率值的加权平均值,权重为其幅度。
- Parameters
- Example
>>> waveform, sample_rate = torchaudio.load('test.wav', normalize=True) >>> transform = transforms.SpectralCentroid(sample_rate) >>> spectral_centroid = transform(waveform) # (channel, time)
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
- Returns
大小为 (…, time) 的频谱质心。
- Return type
张量
语音活动检测¶
-
class
torchaudio.transforms.Vad(sample_rate: int, trigger_level: float = 7.0, trigger_time: float = 0.25, search_time: float = 1.0, allowed_gap: float = 0.25, pre_trigger_time: float = 0.0, boot_time: float = 0.35, noise_up_time: float = 0.1, noise_down_time: float = 0.01, noise_reduction_amount: float = 1.35, measure_freq: float = 20.0, measure_duration: Optional[float] = None, measure_smooth_time: float = 0.4, hp_filter_freq: float = 50.0, lp_filter_freq: float = 6000.0, hp_lifter_freq: float = 150.0, lp_lifter_freq: float = 2000.0)[source]¶ 语音活动检测器。实现方式与 SoX 类似。
尝试从语音录音的开头和结尾修剪静音及安静的背景声音。 该算法目前使用简单的倒谱功率测量来检测人声, 因此可能会被其他事物(尤其是音乐)所误导。
该效果仅能从音频前端进行修剪,因此若要从后端修剪,还必须使用反向效果。
- Parameters
sample_rate (int) – 音频信号的采样率。
trigger_level (float, optional) – 用于触发活动检测的测量级别。 根据噪声水平、信号水平以及输入音频的其他特性,可能需要对此进行调整。(默认值:7.0)
trigger_time (float, optional) – 时间常数(单位:秒),用于帮助忽略短促的声脉冲。(默认值:0.25)
search_time (float, optional) – 在检测到的触发点之前,要搜索以包含更安静或更短音频片段的时长(以秒为单位)。(默认值:1.0)
allowed_gap (float, optional) – 在检测到触发点之前,允许包含的较安静/较短音频片段之间的间隔(以秒为单位)。(默认值:0.25)
pre_trigger_time (float, optional) – 在触发点及任何发现的更安静/更短突发之前要保留的音频量(以秒为单位)。(默认值:0.0)
boot_time (float, optional) 算法(内部)– 用于检测所需音频开始的估计/缩减。此选项设置初始噪声估计的时间。(默认值:0.35)
noise_up_time (float, optional) – 用于噪声水平增加时。(默认值:0.1)
noise_down_time (float, optional) – 用于噪声水平下降时。(默认值:0.01)
noise_reduction_amount (float, optional) – 检测算法(例如 0, 0.5, …)。(默认值:1.35)
measure_freq (float, 可选) – 处理/测量。(默认值:20.0)
measure_duration – (float 或 None,可选) 测量持续时间。 (默认值:测量周期的两倍;即存在重叠。)
measure_smooth_time (float, 可选) – 频谱测量。(默认值:0.4)
hp_filter_freq (float, optional) – 在检测算法的输入端。(默认值:50.0)
lp_filter_freq (float, optional) – 在检测算法的输入端。 (默认值: 6000.0)
hp_lifter_freq (float, 可选) – 在检测器算法中。(默认值:150.0)
lp_lifter_freq (float, 可选) – 在检测器算法中。(默认值:2000.0)
- Reference:
-
forward(waveform: torch.Tensor) → torch.Tensor[source]¶ - Parameters
waveform (Tensor) – 维度为 (channels, time) 或 (time) 的音频张量 形状为 (channels, time) 的张量被视为同一事件的多通道录音,生成的输出将裁剪至任意通道中最早的声音活动。
损失¶
RNNTLoss¶
-
class
torchaudio.transforms.RNNTLoss(blank: int = - 1, clamp: float = - 1.0, reduction: str = 'mean')[source]¶ 计算来自基于循环神经网络的序列转导的RNN Transducer损失 [5]。
RNN Transducer 损失通过定义所有长度输出序列上的分布,并联合建模输入 - 输出和输出 - 输出依赖关系,扩展了 CTC 损失。
- Parameters
- Example
>>> # Hypothetical values >>> logits = torch.tensor([[[[0.1, 0.6, 0.1, 0.1, 0.1], >>> [0.1, 0.1, 0.6, 0.1, 0.1], >>> [0.1, 0.1, 0.2, 0.8, 0.1]], >>> [[0.1, 0.6, 0.1, 0.1, 0.1], >>> [0.1, 0.1, 0.2, 0.1, 0.1], >>> [0.7, 0.1, 0.2, 0.1, 0.1]]]], >>> dtype=torch.float32, >>> requires_grad=True) >>> targets = torch.tensor([[1, 2]], dtype=torch.int) >>> logit_lengths = torch.tensor([2], dtype=torch.int) >>> target_lengths = torch.tensor([2], dtype=torch.int) >>> transform = transforms.RNNTLoss(blank=0) >>> loss = transform(logits, targets, logit_lengths, target_lengths) >>> loss.backward()
-
forward(logits: torch.Tensor, targets: torch.Tensor, logit_lengths: torch.Tensor, target_lengths: torch.Tensor)[source]¶ - Parameters
logits (Tensor) – 维度为 (batch, max seq length, max target length + 1, class) 的张量,包含来自 joiner 的输出
targets (Tensor) – 维度为 (batch, max target length) 的张量,包含经过零填充的目标值
logit_lengths (Tensor) – 维度为 (batch) 的张量,包含来自编码器的每个序列的长度
target_lengths (Tensor) – 维度为 (batch) 的张量,包含每个序列的目标长度
- Returns
应用 reduction 选项后的损失。如果
reduction是'none',则为大小(批次),否则为标量。- Return type
张量
Multi-channel¶
PSD¶
-
class
torchaudio.transforms.PSD(multi_mask: bool = False, normalize: bool = True, eps: float = 1e-15)[source]¶ 计算跨通道功率谱密度 (PSD) 矩阵。
- Parameters
- Tutorials using
PSD:
-
forward(specgram: torch.Tensor, mask: Optional[torch.Tensor] = None)[source]¶ - Parameters
specgram (torch.Tensor) – 多通道复数频谱。 维度为 (…, channel, freq, time) 的张量。
mask (torch.Tensor 或 None, 可选) – 用于归一化的时频掩码。 如果 multi_mask 为
False,则张量维度为 (…, freq, time); 如果 multi_mask 为True,则张量维度为 (…, channel, freq, time)。 (默认值:None)
- Returns
- The complex-valued PSD matrix of the input spectrum.
维度为 (…, freq, channel, channel) 的张量
- Return type
MVDR¶
-
class
torchaudio.transforms.MVDR(ref_channel: int = 0, solution: str = 'ref_channel', multi_mask: bool = False, diag_loading: bool = True, diag_eps: float = 1e-07, online: bool = False)[source]¶ 最小方差无失真响应 (MVDR) 模块,利用时频掩码执行 MVDR 波束成形。
基于 https://github.com/espnet/espnet/blob/master/espnet2/enh/layers/beamformer.py
我们提供三种MVDR波束成形解决方案。其中一种基于参考信道选择 [6] (
solution=ref_channel)。\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bf{\Phi}_{\textbf{SS}}}}(f)} {\text{Trace}({{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f) \bf{\Phi}_{\textbf{SS}}}(f))}}\bm{u} \]其中 \(\bf{\Phi}_{\textbf{SS}}\) 和 \(\bf{\Phi}_{\textbf{NN}}\) 分别是语音和噪声的协方差矩阵。\(\bf{u}\) 是一个独热向量,用于确定参考通道。
另外两个解决方案基于导向矢量(
solution=stv_evd或solution=stv_power)。\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)}} {{\bm{v}^{\mathsf{H}}}(f){\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)} \]其中 \(\bm{v}\) 是声传递函数或导向矢量。 \(.^{\mathsf{H}}\) 表示厄米共轭运算。
我们应用特征值分解 [7] 或 幂法 [8] 从语音的功率谱密度矩阵中获取导向矢量。
在估计波束成形权重后,通过以下方式获得增强后的短时傅里叶变换(STFT)
\[\hat{\bf{S}} = {\bf{w}^\mathsf{H}}{\bf{Y}}, {\bf{w}} \in \mathbb{C}^{M \times F} \]其中 \(\bf{Y}\) 和 \(\hat{\bf{S}}\) 分别是多通道含噪语音和单通道增强语音的短时傅里叶变换(STFT)。
对于在线流式音频,我们提供了一种 递归方法 [9] 来分别更新语音和噪声的功率谱密度(PSD)矩阵。
- Parameters
ref_channel (int, optional) – 波束成形的参考通道。(默认值:
0)solution (str, optional) – 用于计算 MVDR 波束成形权重的解决方案。 选项:[
ref_channel,stv_evd,stv_power]。(默认值:ref_channel)multi_mask (bool, optional) – 如果为
True,则仅接受多通道时频掩码。(默认值:False)diagonal_loading (bool, optional) – 如果为
True,则启用对噪声协方差矩阵应用对角加载。(默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)online (bool, optional) – 如果为
True,则根据先前的协方差矩阵更新 MVDR 波束成形权重。(默认值:False)
注意
为了提高数值稳定性,输入频谱图将转换为双精度(
torch.complex128或torch.cdouble)数据类型以进行内部计算。输出频谱图将转换回与输入频谱图相同的数据类型,以便与其他模块兼容。注意
如果您使用
stv_evd方案,如果 PSD 矩阵的特征值不唯一(即某些特征值接近或相同),则相同输入的梯度可能不完全一致。-
forward(specgram: torch.Tensor, mask_s: torch.Tensor, mask_n: Optional[torch.Tensor] = None) → torch.Tensor[source]¶ 执行 MVDR 波束成形。
- Parameters
specgram (torch.Tensor) – 多通道复数频谱。 维度为 (…, channel, freq, time) 的张量
mask_s (torch.Tensor) – 目标语音的时频掩码。 如果 multi_mask 为
False,则张量维度为 (…, freq, time); 如果 multi_mask 为True,则张量维度为 (…, channel, freq, time)。mask_n (torch.Tensor 或 None, 可选) – 噪声的时频掩码。 如果 multi_mask 为
False,则张量维度为 (…, freq, time); 如果 multi_mask 为True,则张量维度为 (…, channel, freq, time)。 (默认值:None)
- Returns
维度为 (…, freq, time) 的单通道复数增强频谱。
- Return type
RTFMVDR¶
-
class
torchaudio.transforms.RTFMVDR[source]¶ 最小方差无失真响应 (MVDR [10]) 模块 基于相对传递函数 (RTF) 和噪声功率谱密度 (PSD) 矩阵。
给定多通道复值频谱 \(\textbf{Y}\)、目标语音的相对传递函数 (RTF) 矩阵或导向矢量 \(\bm{v}\)、噪声的功率谱密度 (PSD) 矩阵 \(\bf{\Phi}_{\textbf{NN}}\),以及表示参考通道的独热向量 \(\bf{u}\),该模块计算增强后语音的单通道复值频谱 \(\hat{\textbf{S}}\)。公式定义如下:
\[\hat{\textbf{S}}(f) = \textbf{w}_{\text{bf}}(f)^{\mathsf{H}} \textbf{Y}(f) \]其中 \(\textbf{w}_{\text{bf}}(f)\) 是第 \(f\) 个频率二进制的 MVDR 波束成形权重, \((.)^{\mathsf{H}}\) 表示厄米共轭运算。
波束成形权重通过以下方式计算:
\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)}} {{\bm{v}^{\mathsf{H}}}(f){\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)} \]- Tutorials using
RTFMVDR:
-
forward(specgram: torch.Tensor, rtf: torch.Tensor, psd_n: torch.Tensor, reference_channel: Union[int, torch.Tensor], diagonal_loading: bool = True, diag_eps: float = 1e-07, eps: float = 1e-08) → torch.Tensor[source]¶ - Parameters
specgram (torch.Tensor) – 多通道复数频谱。 维度为 (…, channel, freq, time) 的张量
rtf (torch.Tensor) – 目标语音的复数值 RTF 向量。 维度为 (…, freq, channel) 的张量。
psd_n (torch.Tensor) – 噪声的复值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
reference_channel (int 或 torch.Tensor) – 指定参考通道。 如果 dtype 为
int,则表示参考通道索引。 如果 dtype 为torch.Tensor,其形状为 (…, channel),其中channel维度 为 one-hot。diagonal_loading (bool, optional) – 如果为
True,则启用对psd_n应用对角加载。 (默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)eps (float, optional) – 在波束成形权重公式的分母中添加的值。 (默认值:
1e-8)
- Returns
维度为 (…, freq, time) 的单通道复数增强频谱。
- Return type
- Tutorials using
SoudenMVDR¶
-
class
torchaudio.transforms.SoudenMVDR[source]¶ 最小方差无失真响应 (MVDR [10]) 模块 基于 Souden et, al. [6] 提出的方法。
给定多通道复值频谱 \(\textbf{Y}\)、目标语音的功率谱密度 (PSD) 矩阵 \(\bf{\Phi}_{\textbf{SS}}\)、噪声的 PSD 矩阵 \(\bf{\Phi}_{\textbf{NN}}\),以及表示参考通道的独热向量 \(\bf{u}\),该模块计算增强后语音的单通道复值频谱 \(\hat{\textbf{S}}\)。公式定义如下:
\[\hat{\textbf{S}}(f) = \textbf{w}_{\text{bf}}(f)^{\mathsf{H}} \textbf{Y}(f) \]其中 \(\textbf{w}_{\text{bf}}(f)\) 是第 \(f\) 个频率二进制的 MVDR 波束成形权重。
波束成形权重通过以下方式计算:
\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bf{\Phi}_{\textbf{SS}}}}(f)} {\text{Trace}({{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f) \bf{\Phi}_{\textbf{SS}}}(f))}}\bm{u} \]- Tutorials using
SoudenMVDR:
-
forward(specgram: torch.Tensor, psd_s: torch.Tensor, psd_n: torch.Tensor, reference_channel: Union[int, torch.Tensor], diagonal_loading: bool = True, diag_eps: float = 1e-07, eps: float = 1e-08) → torch.Tensor[source]¶ - Parameters
specgram (torch.Tensor) – 多通道复数频谱。 维度为 (…, channel, freq, time) 的张量。
psd_s (torch.Tensor) – 目标语音的复数值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
psd_n (torch.Tensor) – 噪声的复值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
reference_channel (int 或 torch.Tensor) – 指定参考通道。 如果 dtype 为
int,则表示参考通道索引。 如果 dtype 为torch.Tensor,其形状为 (…, channel),其中channel维度 为 one-hot。diagonal_loading (bool, optional) – 如果为
True,则启用对psd_n应用对角加载。 (默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)eps (float, optional) – 在波束成形权重公式的分母中添加的值。 (默认值:
1e-8)
- Returns
维度为 (…, freq, time) 的单通道复数增强频谱。
- Return type
- Tutorials using
参考文献¶
- 1(1,2,3)
Daniel S. Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D. Cubuk, and Quoc V. Le. Specaugment: 一种用于自动语音识别的简单数据增强方法。Interspeech 2019, 2019年9月。URL: http://dx.doi.org/10.21437/Interspeech.2019-2680, doi:10.21437/interspeech.2019-2680.
- 2
Brian McFee, Colin Raffel, Dawen Liang, Daniel P.W. Ellis, Matt McVicar, Eric Battenberg, 和 Oriol Nieto。Librosa:使用 Python 进行音频和音乐信号分析。收录于 Kathryn Huff 和 James Bergstra 编辑的《第 14 届 Python 科学会议论文集》中,第 18 – 24 页。2015 年。doi:10.25080/Majora-7b98e3ed-003.
- 3
Nathanaël Perraudin, Peter Balazs, 和 Peter L. Søndergaard。一种快速的Griffin-Lim算法。发表于 2013 IEEE 信号处理在音频与声学中的应用研讨会,卷,1–4。2013。 doi:10.1109/WASPAA.2013.6701851。
- 4
D. Griffin 和 Jae Lim. 基于修正短时傅里叶变换的信号估计。收录于 ICASSP ‘83. IEEE 声学、语音与信号处理国际会议,第 8 卷,804–807 页。1983 年。doi:10.1109/ICASSP.1983.1172092。
- 5
Alex Graves. 使用循环神经网络进行序列转换。2012. arXiv:1211.3711.
- 6(1,2)
Mehrez Souden, Jacob Benesty, 和 Sofiene Affes. 关于噪声抑制的最优频域多通道线性滤波. 在 IEEE音频、语音和语言处理汇刊, 第18卷, 260–276页. IEEE, 2009.
- 7
Takuya Higuchi, Nobutaka Ito, Takuya Yoshioka, 和 Tomohiro Nakatani。使用时频掩码的鲁棒mvdr波束成形,用于噪声环境下的在线/离线语音识别。发表于 2016 IEEE国际声学、语音与信号处理会议(ICASSP),5210–5214。IEEE,2016年。
- 8
RV Mises 和 Hilda Pollaczek-Geiringer. 解方程的实用方法。 ZAMM-应用数学与力学杂志/Zeitschrift für Angewandte Mathematik und Mechanik, 9(1):58–77, 1929.
- 9
Takuya Higuchi, Nobutaka Ito, Shoko Araki, Takuya Yoshioka, Marc Delcroix, 和 Tomohiro Nakatani. 基于具有空间先验的复高斯混合模型的在线MVDR波束成形器,用于噪声鲁棒的ASR。IEEE/ACM音频、语音和语言处理汇刊, 25(4):780–793, 2017.
- 10(1,2)
Jack Capon。高分辨率频率-波数谱分析。IEEE proceedings, 57(8):1408–1418, 1969。