torchaudio.functional¶
执行常见音频操作的函数。
实用工具¶
amplitude_to_DB¶
-
torchaudio.functional.amplitude_to_DB(x: torch.Tensor, multiplier: float, amin: float, db_multiplier: float, top_db: Optional[float] = None) → torch.Tensor[source]¶ 将频谱图从功率/幅度刻度转换为分贝刻度。


批次中每个张量的输出取决于该张量的最大值,因此对于分割成片段与完整片段的音频剪辑,可能会返回不同的值。
- Parameters
- Returns
以分贝刻度输出的张量
- Return type
张量
DB_to_amplitude¶
-
torchaudio.functional.DB_to_amplitude(x: torch.Tensor, ref: float, power: float) → torch.Tensor[source]¶ 将张量从分贝刻度转换为功率/幅度刻度。

melscale_fbanks¶
-
torchaudio.functional.melscale_fbanks(n_freqs: int, f_min: float, f_max: float, n_mels: int, sample_rate: int, norm: Optional[str] = None, mel_scale: str = 'htk') → torch.Tensor[source]¶ 创建频率分箱转换矩阵。

注意
为了与 librosa 保持数值兼容性,生成的滤波器组中并非所有系数的幅度都为 1。
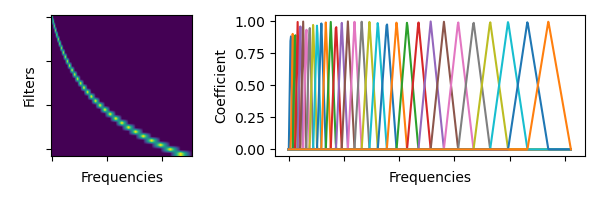
- Parameters
- Returns
大小为 (
n_freqs,n_mels) 的三角形滤波器组(fb 矩阵) 意味着要突出显示/应用于 x 的频率数量,即滤波器组的数量。 每一列都是一个滤波器组,因此假设存在一个大小为 (…,n_freqs) 的矩阵 A,应用后的结果将是A * melscale_fbanks(A.size(-1), ...)。- Return type
张量
- Tutorials using
melscale_fbanks:
linear_fbanks¶
-
torchaudio.functional.linear_fbanks(n_freqs: int, f_min: float, f_max: float, n_filter: int, sample_rate: int) → torch.Tensor[source]¶ 创建一个线性三角滤波器组。
注意
为了与 librosa 保持数值兼容性,生成的滤波器组中并非所有系数的幅度都为 1。
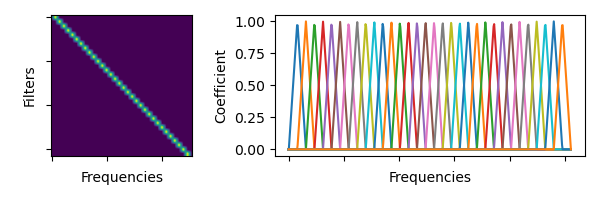
- Parameters
- Returns
大小为 (
n_freqs,n_filter) 的三角形滤波器组(fb 矩阵) 意味着要突出显示/应用于 x 的频率数量,即滤波器组的数量。 每一列都是一个滤波器组,因此假设存在一个大小为 (…,n_freqs) 的矩阵 A,应用后的结果将是A * linear_fbanks(A.size(-1), ...)。- Return type
张量
create_dct¶
mask_along_axis¶
-
torchaudio.functional.mask_along_axis(specgram: torch.Tensor, mask_param: int, mask_value: float, axis: int, p: float = 1.0) → torch.Tensor[source]¶ 沿
axis应用掩码。
掩码将从索引
[v_0, v_0 + v)开始应用, 其中v从uniform(0, max_v)中采样,v_0从uniform(0, specgrams.size(axis) - v)中采样, 当p = 1.0时为max_v = mask_param, 否则为max_v = min(mask_param, floor(specgrams.size(axis) * p))。 所有示例将具有相同的掩码间隔。
mask_along_axis_iid¶
-
torchaudio.functional.mask_along_axis_iid(specgrams: torch.Tensor, mask_param: int, mask_value: float, axis: int, p: float = 1.0) → torch.Tensor[source]¶ 沿
axis应用掩码。
掩码将从索引
[v_0, v_0 + v)开始应用, 其中v从uniform(0, max_v)中采样,v_0从uniform(0, specgrams.size(axis) - v)中采样, 当p = 1.0时为max_v = mask_param, 否则为max_v = min(mask_param, floor(specgrams.size(axis) * p))。
mu_law_encoding¶
-
torchaudio.functional.mu_law_encoding(x: torch.Tensor, quantization_channels: int) → torch.Tensor[source]¶ 基于 μ 律压扩对信号进行编码。
有关更多信息,请参见 维基百科条目
该算法期望信号已缩放到 -1 到 1 之间,并返回一个编码值范围为 0 到 quantization_channels - 1 的信号。
- Parameters
x (Tensor) – 输入张量
quantization_channels (int) – 通道数量
- Returns
经过 μ 律编码后的输入
- Return type
张量
mu_law_decoding¶
-
torchaudio.functional.mu_law_decoding(x_mu: torch.Tensor, quantization_channels: int) → torch.Tensor[source]¶ 解码 μ 律编码信号。
有关更多信息,请参见 维基百科条目
此函数期望输入值在 0 到 quantization_channels - 1 之间,并返回一个缩放至 -1 到 1 之间的信号。
- Parameters
x_mu (Tensor) – 输入张量
quantization_channels (int) – 通道数量
- Returns
经过 μ 律解码后的输入
- Return type
张量
apply_codec¶
-
torchaudio.functional.apply_codec(waveform: torch.Tensor, sample_rate: int, format: str, channels_first: bool = True, compression: Optional[float] = None, encoding: Optional[str] = None, bits_per_sample: Optional[int] = None) → torch.Tensor[source]¶ 将编解码器作为一种增强形式进行应用。
- Parameters
waveform (Tensor) – 音频数据。必须是二维的。另见
`channels_first`。sample_rate (int) – 音频波形的采样率。
format (str) – 文件格式。
channels_first (bool, optional) – 当为 True 时,输入和输出张量的维度均为 (channel, time)。 否则,它们的维度为 (time, channel)。
compression (float 或 None, 可选) – 用于 WAV 以外的格式。 更多详情请参见
torchaudio.backend.sox_io_backend.save()。encoding (str 或 None, 可选) – 更改支持格式的编码。 更多详情请参见
torchaudio.backend.sox_io_backend.save()。bits_per_sample (int 或 None, 可选) – 更改支持格式的位深度。 更多详情请参见
torchaudio.backend.sox_io_backend.save()。
- Returns
生成的张量。 如果
channels_first=True,则为 (channel, time),否则为 (time, channel)。- Return type
张量
- Tutorials using
apply_codec:
重采样¶
-
torchaudio.functional.resample(waveform: torch.Tensor, orig_freq: int, new_freq: int, lowpass_filter_width: int = 6, rolloff: float = 0.99, resampling_method: str = 'sinc_interpolation', beta: Optional[float] = None) → torch.Tensor[source]¶ 使用带限插值以新频率对波形进行重采样。 [1].
注意
transforms.Resample预计算并重用重采样核,因此如果使用相同的重采样参数对多个波形进行重采样,将能实现更高效的计算。- Parameters
waveform (Tensor) – 维度为 (…, time) 的输入信号
orig_freq (int) – 信号的原始频率
new_freq (int) – 期望的频率
lowpass_filter_width (int, optional) – 控制滤波器的锐度,值越大越锐利但效率越低。(默认值:
6)rolloff (float, optional) – 滤波器的滚降频率,表示为奈奎斯特频率的分数。 较低的值会减少抗混叠效果,但也会降低部分最高频率。(默认值:
0.99)resampling_method (str, optional) – 要使用的重采样方法。 选项:[
sinc_interpolation,kaiser_window](默认值:'sinc_interpolation')
- Returns
维度 (…, time). 新频率处的波形
- Return type
张量
- Tutorials using
resample:

过滤¶
allpass_biquad¶
-
torchaudio.functional.allpass_biquad(waveform: torch.Tensor, sample_rate: int, central_freq: float, Q: float = 0.707) → torch.Tensor[source]¶ 设计二阶全通滤波器。实现方式与 SoX 类似。
- Parameters
waveform (torch.Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
central_freq (float 或 torch.Tensor) – 中心频率(单位:Hz)
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)
- Returns
维度为 (…, time) 的波形
- Return type
张量
band_biquad¶
-
torchaudio.functional.band_biquad(waveform: torch.Tensor, sample_rate: int, central_freq: float, Q: float = 0.707, noise: bool = False) → torch.Tensor[source]¶ 设计二极点带通滤波器。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
central_freq (float 或 torch.Tensor) – 中心频率(单位:Hz)
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)。noise (bool, optional) – 如果为
True,则使用非音高音频(例如打击乐)的替代模式。 如果为False,则使用面向音高音频的模式,即人声、歌唱或器乐音乐(默认值:False)。
- Returns
维度为 (…, time) 的波形
- Return type
张量
bandpass_biquad¶
-
torchaudio.functional.bandpass_biquad(waveform: torch.Tensor, sample_rate: int, central_freq: float, Q: float = 0.707, const_skirt_gain: bool = False) → torch.Tensor[source]¶ 设计二极点带通滤波器。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
central_freq (float 或 torch.Tensor) – 中心频率(单位:Hz)
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)const_skirt_gain (bool, optional) – 如果为
True,则使用恒定裙边增益(峰值增益 = Q)。 如果为False,则使用恒定的 0dB 峰值增益。(默认值:False)
- Returns
维度为 (…, time) 的波形
- Return type
张量
bandreject_biquad¶
-
torchaudio.functional.bandreject_biquad(waveform: torch.Tensor, sample_rate: int, central_freq: float, Q: float = 0.707) → torch.Tensor[source]¶ 设计二阶带阻滤波器。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
central_freq (float 或 torch.Tensor) – 中心频率(单位:Hz)
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)
- Returns
维度为 (…, time) 的波形
- Return type
张量
bass_biquad¶
-
torchaudio.functional.bass_biquad(waveform: torch.Tensor, sample_rate: int, gain: float, central_freq: float = 100, Q: float = 0.707) → torch.Tensor[source]¶ 设计一个低音音调控制效果。类似于 SoX 的实现。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
gain (float 或 torch.Tensor) – 在增益(或衰减)处期望的 dB 值。
central_freq (float 或 torch.Tensor, 可选) – 中心频率(单位:Hz)。(默认值:
100)Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)。
- Returns
维度为 (…, time) 的波形
- Return type
张量
二阶节¶
-
torchaudio.functional.biquad(waveform: torch.Tensor, b0: float, b1: float, b2: float, a0: float, a1: float, a2: float) → torch.Tensor[source]¶ 对输入张量执行双二阶滤波器处理。初始条件设为 0。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
b0 (float 或 torch.Tensor) – 当前输入 x[n] 的分子系数
b1 (float 或 torch.Tensor) – 一个时间步之前输入 x[n-1] 的分子系数
b2 (float 或 torch.Tensor) – 两个时间步之前的输入 x[n-2] 的分子系数
a0 (float 或 torch.Tensor) – 当前输出 y[n] 的分母系数,通常为 1
a1 (float 或 torch.Tensor) – 当前输出 y[n-1] 的分母系数
a2 (float 或 torch.Tensor) – 当前输出 y[n-2] 的分母系数
- Returns
维度为 (…, time) 的波形
- Return type
张量
对比度¶
-
torchaudio.functional.contrast(waveform: torch.Tensor, enhancement_amount: float = 75.0) → torch.Tensor[source]¶ 应用对比效果。与 SoX 实现类似。
与压缩效果类似,该效果通过修改音频信号使其听起来更响亮。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
enhancement_amount (float, optional) – 控制增强的幅度 enhancement_amount 的允许值范围:0-100 请注意,即使 enhancement_amount = 0 也会产生显著的对比度增强
- Returns
维度为 (…, time) 的波形
- Return type
张量
- Reference:
dcshift¶
-
torchaudio.functional.dcshift(waveform: torch.Tensor, shift: float, limiter_gain: Optional[float] = None) → torch.Tensor[source]¶ 对音频应用直流偏移。实现方式与 SoX 类似。
这有助于从音频中去除直流偏移(可能是由录音链中的硬件问题引起的)。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
shift (float) – 指示音频的移位量 shift 允许的值范围:-2.0 到 +2.0
limiter_gain (float 或 None, 可选) – 仅用于峰值以防止削波 其值应远小于 1(例如 0.05 或 0.02)
- Returns
维度为 (…, time) 的波形
- Return type
张量
- Reference:
deemph_biquad¶
-
torchaudio.functional.deemph_biquad(waveform: torch.Tensor, sample_rate: int) → torch.Tensor[source]¶ 应用 ISO 908 CD 去加重(搁架)IIR 滤波器。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,允许的采样率为
44100或48000
- Returns
维度为 (…, time) 的波形
- Return type
张量
抖动¶
-
torchaudio.functional.dither(waveform: torch.Tensor, density_function: str = 'TPDF', noise_shaping: bool = False) → torch.Tensor[source]¶ 应用抖动
抖动通过在特定位深度存储的音频中消除非线性截断失真(即添加最小可感知噪声以掩盖量化引起的失真),提高了音频的感知动态范围。
equalizer_biquad¶
-
torchaudio.functional.equalizer_biquad(waveform: torch.Tensor, sample_rate: int, center_freq: float, gain: float, Q: float = 0.707) → torch.Tensor[source]¶ 设计双二阶峰值均衡器滤波器并执行滤波操作。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
center_freq (float) – 滤波器的中心频率
gain (float 或 torch.Tensor) – 在增益(或衰减)处所需的 dB 值
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)
- Returns
维度为 (…, time) 的波形
- Return type
张量
filtfilt¶
-
torchaudio.functional.filtfilt(waveform: torch.Tensor, a_coeffs: torch.Tensor, b_coeffs: torch.Tensor, clamp: bool = True) → torch.Tensor[source]¶ 对波形应用前向和后向 IIR 滤波器。
受 https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.filtfilt.html 启发
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形。必须归一化到 -1 到 1 之间。
a_coeffs (Tensor) – 差分方程的分母系数,维度为 1D(形状为 (num_order + 1))或 2D(形状为 (num_filters, num_order + 1))。 低延迟系数排在前面,例如
[a0, a1, a2, ...]。 必须与 b_coeffs 大小相同(必要时用 0 填充)。b_coeffs (Tensor) – 差分方程的分子系数,维度为 1D(形状为 (num_order + 1))或 2D(形状为 (num_filters, num_order + 1))。 低延迟系数排在前面,例如
[b0, b1, b2, ...]。 必须与 a_coeffs 大小相同(必要时用 0 填充)。clamp (bool, optional) – 如果为
True,则将输出信号限制在 [-1, 1] 范围内(默认值:True)
- Returns
波形维度为 (…, num_filters, time)(如果
a_coeffs和b_coeffs是二维张量),否则为 (…, time)。- Return type
张量
flanger¶
-
torchaudio.functional.flanger(waveform: torch.Tensor, sample_rate: int, delay: float = 0.0, depth: float = 2.0, regen: float = 0.0, width: float = 71.0, speed: float = 0.5, phase: float = 25.0, modulation: str = 'sinusoidal', interpolation: str = 'linear') → torch.Tensor[source]¶ 对音频应用镶边效果。实现方式类似于 SoX。
- Parameters
waveform (Tensor) – 维度为 (…, channel, time) 的音频波形。 最多允许 4 个通道
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
delay (float, optional) – 期望的延迟时间(毫秒,ms) 允许的取值范围为 0 到 30
depth (float, optional) – 期望的延迟深度,单位为毫秒(ms) 允许的值范围为 0 到 10
regen (float, optional) – 期望的再生(反馈增益),单位为 dB 允许的取值范围是 -95 到 95
width (float, optional) – 期望的宽度(延迟增益),单位为 dB 允许的取值范围为 0 到 100
speed (float, optional) – 赫兹 (Hz) 单位的调制速度 允许的取值范围为 0.1 到 10
phase (float, optional) – 多通道的百分比相位偏移 允许的值范围为 0 到 100
modulation (str, optional) – 使用“正弦”或“三角”调制。(默认:
sinusoidal)interpolation (str, optional) – 使用“linear”或“quadratic”进行延迟线插值。 (默认:
linear)
- Returns
维度为 (…, channel, time) 的波形
- Return type
张量
- Reference:
Scott Lehman, 效果解释,
增益¶
-
torchaudio.functional.gain(waveform: torch.Tensor, gain_db: float = 1.0) → torch.Tensor[source]¶ 对整个波形应用放大或衰减。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量。
gain_db (float, 可选) 分贝增益调整 (dB) –
1.0).
- Returns
整个波形被 gain_db 放大。
- Return type
张量
highpass_biquad¶
-
torchaudio.functional.highpass_biquad(waveform: torch.Tensor, sample_rate: int, cutoff_freq: float, Q: float = 0.707) → torch.Tensor[source]¶ 设计二阶高通滤波器并执行滤波操作。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
cutoff_freq (float 或 torch.Tensor) – 滤波器截止频率
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)
- Returns
波形维度为 (…, time)
- Return type
张量
lfilter¶
-
torchaudio.functional.lfilter(waveform: torch.Tensor, a_coeffs: torch.Tensor, b_coeffs: torch.Tensor, clamp: bool = True, batching: bool = True) → torch.Tensor[source]¶ 通过评估差分方程执行 IIR 滤波。
注意
为避免数值问题,建议使用较小的滤波器阶数。 使用双精度也可最大限度地减少数值精度误差。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形。必须归一化到 -1 到 1 之间。
a_coeffs (Tensor) – 差分方程的分母系数,维度为 1D(形状为 (num_order + 1))或 2D(形状为 (num_filters, num_order + 1))。 低延迟系数排在前面,例如
[a0, a1, a2, ...]。 必须与 b_coeffs 大小相同(必要时用 0 填充)。b_coeffs (Tensor) – 差分方程的分子系数,维度为 1D(形状为 (num_order + 1))或 2D(形状为 (num_filters, num_order + 1))。 较低延迟的系数排在前面,例如
[b0, b1, b2, ...]。 必须与 a_coeffs 大小相同(必要时用 0 填充)。clamp (bool, optional) – 如果为
True,则将输出信号限制在 [-1, 1] 范围内(默认值:True)batching (bool, optional) – 仅当系数为二维时有效。如果
True,则波形应至少为二维,且从最后数第二个轴的大小应等于num_filters。输出可以表示为output[..., i, :] = lfilter(waveform[..., i, :], a_coeffs[i], b_coeffs[i], clamp=clamp, batching=False)。(默认值:True)
- Returns
波形维度为 (…, num_filters, time)(如果
a_coeffs和b_coeffs是二维张量),否则为 (…, time)。- Return type
张量
lowpass_biquad¶
-
torchaudio.functional.lowpass_biquad(waveform: torch.Tensor, sample_rate: int, cutoff_freq: float, Q: float = 0.707) → torch.Tensor[source]¶ 设计二阶低通滤波器并执行滤波操作。实现方式与 SoX 类似。
- Parameters
waveform (torch.Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
cutoff_freq (float 或 torch.Tensor) – 滤波器截止频率
Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)
- Returns
维度为 (…, time) 的波形
- Return type
张量
overdrive¶
-
torchaudio.functional.overdrive(waveform: torch.Tensor, gain: float = 20, colour: float = 20) → torch.Tensor[source]¶ 对音频应用过载效果。类似于 SoX 的实现。
此效果会对音频信号施加非线性失真。
- Parameters
- Returns
维度为 (…, time) 的波形
- Return type
张量
- Reference:
phaser¶
-
torchaudio.functional.phaser(waveform: torch.Tensor, sample_rate: int, gain_in: float = 0.4, gain_out: float = 0.74, delay_ms: float = 3.0, decay: float = 0.4, mod_speed: float = 0.5, sinusoidal: bool = True) → torch.Tensor[source]¶ 对音频应用相位效果。类似于 SoX 的实现。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
gain_in (float, optional) – 增强(或衰减)时所需的输入增益,单位为 dB 允许的值范围为 0 到 1
gain_out (float, optional) – 在增强(或衰减)时所需的输出增益,单位为 dB 允许的取值范围是 0 到 1e9
delay_ms (float, optional) – 期望的延迟(毫秒) 允许的取值范围为 0 到 5.0
decay (float, optional) – 相对于增益的期望衰减量 允许的值范围是 0 到 0.99
mod_speed (float, optional) – 调制速度,单位为赫兹 (Hz) 允许的取值范围为 0.1 到 2
sinusoidal (bool, optional) – 如果为
True,则使用正弦调制(适用于多种乐器) 如果为False,则使用三角波调制(可为单一乐器提供更清晰的相位效果) (默认值:True)
- Returns
维度为 (…, time) 的波形
- Return type
张量
- Reference:
Scott Lehman, 效果解释.
riaa_biquad¶
-
torchaudio.functional.riaa_biquad(waveform: torch.Tensor, sample_rate: int) → torch.Tensor[source]¶ 应用 RIAA 黑胶唱片播放均衡化。实现方式与 SoX 类似。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)。 允许的采样率(单位:Hz):
44100,``48000``,``88200``,``96000``
- Returns
维度为 (…, time) 的波形
- Return type
张量
treble_biquad¶
-
torchaudio.functional.treble_biquad(waveform: torch.Tensor, sample_rate: int, gain: float, central_freq: float = 3000, Q: float = 0.707) → torch.Tensor[source]¶ 设计一个三波段音调控制效果。类似于 SoX 的实现。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频波形
sample_rate (int) – 波形的采样率,例如 44100 (Hz)
gain (float 或 torch.Tensor) – 在增益(或衰减)处期望的 dB 值。
central_freq (float 或 torch.Tensor, 可选) – 中心频率(单位:Hz)。(默认值:
3000)Q (float 或 torch.Tensor, 可选) – https://en.wikipedia.org/wiki/Q_factor (默认值:
0.707)。
- Returns
维度为 (…, time) 的波形
- Return type
张量
特征提取¶
语音活动检测¶
-
torchaudio.functional.vad(waveform: torch.Tensor, sample_rate: int, trigger_level: float = 7.0, trigger_time: float = 0.25, search_time: float = 1.0, allowed_gap: float = 0.25, pre_trigger_time: float = 0.0, boot_time: float = 0.35, noise_up_time: float = 0.1, noise_down_time: float = 0.01, noise_reduction_amount: float = 1.35, measure_freq: float = 20.0, measure_duration: Optional[float] = None, measure_smooth_time: float = 0.4, hp_filter_freq: float = 50.0, lp_filter_freq: float = 6000.0, hp_lifter_freq: float = 150.0, lp_lifter_freq: float = 2000.0) → torch.Tensor[source]¶ 语音活动检测器。实现方式与 SoX 类似。
尝试从语音录音的开头和结尾修剪静音及安静的背景声音。 该算法目前使用简单的倒谱功率测量来检测人声, 因此可能会被其他事物(尤其是音乐)所误导。
该效果仅能从音频前端进行修剪,因此若要从后端修剪,还必须使用反向效果。
- Parameters
waveform (Tensor) – 维度为 (channels, time) 或 (time) 的音频张量 形状为 (channels, time) 的张量被视为同一事件的多通道录音,生成的输出将裁剪至任意通道中最早的声音活动。
sample_rate (int) – 音频信号的采样率。
trigger_level (float, optional) – 用于触发活动检测的测量级别。 根据噪声水平、信号水平以及输入音频的其他特性,可能需要对此进行调整。(默认值:7.0)
trigger_time (float, optional) – 时间常数(单位:秒),用于帮助忽略短促的声脉冲。(默认值:0.25)
search_time (float, optional) – 在检测到的触发点之前,要搜索以包含更安静或更短音频片段的时长(以秒为单位)。(默认值:1.0)
allowed_gap (float, optional) – 在检测到触发点之前,允许包含的较安静/较短音频片段之间的间隔(以秒为单位)。(默认值:0.25)
pre_trigger_time (float, optional) – 在触发点及任何发现的更安静/更短突发之前要保留的音频量(以秒为单位)。(默认值:0.0)
boot_time (float, optional) 算法(内部)– 用于检测所需音频开始的估计/缩减。此选项设置初始噪声估计的时间。(默认值:0.35)
noise_up_time (float, optional) – 用于噪声水平增加时。(默认值:0.1)
noise_down_time (float, optional) – 用于噪声水平下降时。(默认值:0.01)
noise_reduction_amount (float, optional) – 检测算法(例如 0, 0.5, …)。(默认值:1.35)
measure_freq (float, 可选) – 处理/测量。(默认值:20.0)
measure_duration – (float, 可选) 测量持续时间。 (默认值:测量周期的两倍;即存在重叠。)
measure_smooth_time (float, 可选) – 频谱测量。(默认值:0.4)
hp_filter_freq (float, optional) – 在检测算法的输入端。(默认值:50.0)
lp_filter_freq (float, optional) – 在检测算法的输入端。 (默认值: 6000.0)
hp_lifter_freq (float, 可选) – 在检测器算法中。(默认值:150.0)
lp_lifter_freq (float, 可选) – 在检测器算法中。(默认值:2000.0)
- Returns
维度为 (…, time) 的音频张量。
- Return type
张量
- Reference:
频谱图¶
-
torchaudio.functional.spectrogram(waveform: torch.Tensor, pad: int, window: torch.Tensor, n_fft: int, hop_length: int, win_length: int, power: Optional[float], normalized: bool, center: bool = True, pad_mode: str = 'reflect', onesided: bool = True, return_complex: Optional[bool] = None) → torch.Tensor[source]¶ 从原始音频信号创建频谱图或一批频谱图。 频谱图可以是仅幅度形式,也可以是复数形式。
- Parameters
waveform (Tensor) – 维度为 (…, time) 的音频张量
pad (int) – 信号的双边填充
window (Tensor) – 应用于/乘以每个帧/窗口的窗口张量
n_fft (int) – FFT 大小
hop_length (int) – STFT 窗口之间的跳跃长度
win_length (int) – 窗口大小
power (float 或 None) – 幅度谱图的指数, (必须 > 0),例如:1 表示能量,2 表示功率等。 如果为 None,则返回复数频谱。
normalized (bool) – 是否在 stft 后按幅度进行归一化
center (bool, optional) – 是否对
waveform两侧进行填充,使得第 \(t\) 帧位于时间 \(t \times \text{hop\_length}\) 的中心。 默认值:Truepad_mode (string, optional) – 控制当
center为True时使用的填充方法。默认值:"reflect"onesided (bool, optional) – 控制是否返回一半的结果以避免冗余。默认值:
Truereturn_complex (bool, optional) – 已弃用且未使用。
- Returns
维度 (…, freq, time),频率为
n_fft // 2 + 1和n_fft是傅里叶分箱的数量,而时间则是窗口跳数的数量(n_frame)。- Return type
张量
inverse_spectrogram¶
-
torchaudio.functional.inverse_spectrogram(spectrogram: torch.Tensor, length: Optional[int], pad: int, window: torch.Tensor, n_fft: int, hop_length: int, win_length: int, normalized: bool, center: bool = True, pad_mode: str = 'reflect', onesided: bool = True) → torch.Tensor[source]¶ 根据提供的复数频谱图,生成逆频谱图或一批逆频谱图。
- Parameters
频谱图 (Tensor) – 维度为 (…, freq, time) 的音频复数张量。
pad (int) – 信号的双边填充。仅在提供
length时有效。window (Tensor) – 应用于/乘以每个帧/窗口的窗口张量
n_fft (int) – FFT 大小
hop_length (int) – STFT 窗口之间的跳跃长度
win_length (int) – 窗口大小
normalized (bool) – 是否已对 stft 输出进行幅度归一化
center (bool, optional) – 是否对波形两侧进行了填充,以便第 \(t\) 帧的中心位于时间 \(t \times \text{hop\_length}\)。 默认值:
Truepad_mode (string, optional) – 控制当
center为True时使用的填充方法。此参数是为了与 spectrogram 函数兼容而提供的,并未使用。默认值:"reflect"onesided (bool, optional) – 控制频谱图是否以单边模式执行。 默认值:
True
- Returns
维度 (…, time)。原始信号的最小二乘估计。
- Return type
张量
格里芬 - 利姆¶
-
torchaudio.functional.griffinlim(specgram: torch.Tensor, window: torch.Tensor, n_fft: int, hop_length: int, win_length: int, power: float, n_iter: int, momentum: float, length: Optional[int], rand_init: bool) → torch.Tensor[source]¶ 使用 Griffin-Lim 变换从线性尺度幅度谱图计算波形。
实现移植自 librosa [2]、A fast Griffin-Lim algorithm [3] 以及 Signal estimation from modified short-time Fourier transform [4]。
- Parameters
specgram (Tensor) – 一个维度为 (…, freq, frames) 的仅包含幅值的 STFT 频谱图,其中 freq 为
n_fft // 2 + 1。window (Tensor) – 应用于/乘以每个帧/窗口的窗口张量
n_fft (int) – FFT 大小,创建
n_fft // 2 + 1个频带hop_length (int) – STFT 窗口之间的跳跃长度。( 默认值:
win_length // 2)win_length (int) – 窗口大小。(默认值:
n_fft)power (float) – 幅度谱的指数, (必须 > 0),例如:1 表示能量,2 表示功率等。
n_iter (int) – 相位恢复过程的迭代次数。
momentum (float) – 快速 Griffin-Lim 的动量参数。 将其设置为 0 可恢复原始的 Griffin-Lim 方法。 接近 1 的值可以导致更快的收敛,但大于 1 可能无法收敛。
rand_init (bool) – 如果为 True,则随机初始化相位;否则初始化为零。
- Returns
(…, time) 的波形,其中时间等于给定的
length参数。- Return type
张量
phase_vocoder¶
-
torchaudio.functional.phase_vocoder(complex_specgrams: torch.Tensor, rate: float, phase_advance: torch.Tensor) → torch.Tensor[source]¶ 给定一个 STFT 张量,在不改变音高的情况下将时间加速
rate倍。
- Parameters
complex_specgrams (Tensor) – 一个维度为 (…, freq, num_frame) 且数据类型为复数的张量。
rate (float) – 加速因子
phase_advance (Tensor) – 每个分箱中预期的相位超前。维度为 (freq, 1)
- Returns
拉伸后的语谱图。生成的张量与输入语谱图具有相同的数据类型,但帧数已更改为
ceil(num_frame / rate)。- Return type
张量
- Example
>>> freq, hop_length = 1025, 512 >>> # (channel, freq, time) >>> complex_specgrams = torch.randn(2, freq, 300, dtype=torch.cfloat) >>> rate = 1.3 # Speed up by 30% >>> phase_advance = torch.linspace( >>> 0, math.pi * hop_length, freq)[..., None] >>> x = phase_vocoder(complex_specgrams, rate, phase_advance) >>> x.shape # with 231 == ceil(300 / 1.3) torch.Size([2, 1025, 231])
pitch_shift¶
-
torchaudio.functional.pitch_shift(waveform: torch.Tensor, sample_rate: int, n_steps: int, bins_per_octave: int = 12, n_fft: int = 512, win_length: Optional[int] = None, hop_length: Optional[int] = None, window: Optional[torch.Tensor] = None) → torch.Tensor[source]¶ 将波形的音高移动
n_steps个步骤。
- Parameters
waveform (Tensor) – 形状为 (…, time) 的输入波形。
sample_rate (int) – waveform的采样率。
n_steps (int) – 用于偏移 waveform 的(分数)步数。
bins_per_octave (int, optional) – 每个八度的步数(默认值:
12)。n_fft (int, optional) – FFT 大小,创建
n_fft // 2 + 1个频带(默认值:512)。win_length (int 或 None, 可选) – 窗口大小。如果为 None,则使用
n_fft。(默认值:None)。hop_length (int 或 None, 可选) – STFT 窗口之间的跳跃长度。如果为 None,则使用
win_length // 4(默认值:None)。window (Tensor 或 None, 可选) – 应用于/乘以每个帧/窗口的窗口张量。 如果为 None,则使用
torch.hann_window(win_length)(默认值:None)。
- Returns
形状为 (…, time) 的移调音频波形。
- Return type
张量
compute_deltas¶
-
torchaudio.functional.compute_deltas(specgram: torch.Tensor, win_length: int = 5, mode: str = 'replicate') → torch.Tensor[source]¶ 计算张量(通常是频谱图)的差分系数:
\[d_t = \frac{\sum_{n=1}^{\text{N}} n (c_{t+n} - c_{t-n})}{2 \sum_{n=1}^{\text{N}} n^2} \]其中 \(d_t\) 是时间 \(t\) 处的增量, \(c_t\) 是时间 \(t\) 处的频谱图系数, \(N\) 是
(win_length-1)//2。- Parameters
- Returns
维度为 (…, freq, time) 的增量张量
- Return type
张量
- Example
>>> specgram = torch.randn(1, 40, 1000) >>> delta = compute_deltas(specgram) >>> delta2 = compute_deltas(delta)
detect_pitch_frequency¶
-
torchaudio.functional.detect_pitch_frequency(waveform: torch.Tensor, sample_rate: int, frame_time: float = 0.01, win_length: int = 30, freq_low: int = 85, freq_high: int = 3400) → torch.Tensor[source]¶ 检测音高频率。
该实现采用归一化互相关函数和中值平滑。
- Parameters
- Returns
维度 (…, frame) 的频率张量
- Return type
张量
- Tutorials using
detect_pitch_frequency:
sliding_window_cmn¶
-
torchaudio.functional.sliding_window_cmn(specgram: torch.Tensor, cmn_window: int = 600, min_cmn_window: int = 100, center: bool = False, norm_vars: bool = False) → torch.Tensor[source]¶ 对每个语音片段应用滑动窗口倒谱均值(以及可选的方差)归一化。
- Parameters
specgram (Tensor) – 维度为 (…, time, freq) 的语谱图张量
cmn_window (int, optional) – 用于计算运行平均CMN的帧数窗口(int,默认值 = 600)
min_cmn_window (int, optional) – 解码开始时使用的最小 CMN 窗口(仅在开始时增加延迟)。 仅当 center == false 时适用,如果 center==true 则被忽略(int,默认值 = 100)
center (bool, optional) – 如果为 true,则使用以当前帧为中心的窗口(在可能的情况下,模去端点效应)。如果为 false,则窗口位于左侧。(bool,默认值 = false)
norm_vars (bool, optional) – 如果为 true,则将方差归一化为 1。(bool,默认值 = false)
- Returns
张量匹配输入形状 (…, freq, time)
- Return type
张量
compute_kaldi_pitch¶
-
torchaudio.functional.compute_kaldi_pitch(waveform: torch.Tensor, sample_rate: float, frame_length: float = 25.0, frame_shift: float = 10.0, min_f0: float = 50, max_f0: float = 400, soft_min_f0: float = 10.0, penalty_factor: float = 0.1, lowpass_cutoff: float = 1000, resample_frequency: float = 4000, delta_pitch: float = 0.005, nccf_ballast: float = 7000, lowpass_filter_width: int = 1, upsample_filter_width: int = 5, max_frames_latency: int = 0, frames_per_chunk: int = 0, simulate_first_pass_online: bool = False, recompute_frame: int = 500, snip_edges: bool = True) → torch.Tensor[source]¶ 根据《一种针对自动语音识别优化的音高提取算法》中描述的方法提取音高 [5]。
此函数计算与 Kaldi 中 compute-kaldi-pitch-feats 等效的结果。
- Parameters
waveform (Tensor) – 形状为 (…, time) 的输入波形。
sample_rate (float) – waveform的采样率。
frame_length (float, optional) – 以毫秒为单位的帧长度。(默认值:25.0)
frame_shift (float, optional) – 帧移,单位:毫秒。(默认值:10.0)
min_f0 (float, optional) – 要搜索的最小 F0(Hz)(默认值:50.0)
max_f0 (float, optional) – 搜索的最大 F0(Hz)(默认值:400.0)
soft_min_f0 (float, optional) – 最小 f0,以柔和方式应用,不得超过 min-f0(默认值:10.0)
penalty_factor (float, optional) – FO 变化的成本因子。(默认值:0.1)
lowpass_cutoff (float, optional) – 低通滤波器的截止频率(Hz)(默认值:1000)
resample_frequency (float, optional) – 我们要将信号下采样到的频率。必须大于低通截止频率的两倍。 (默认值:4000)
delta_pitch (float, optional) – 我们的算法测量的最小相对音高变化。(默认值:0.005)
nccf_ballast (float, optional) – 增加此因子可降低静音帧的 NCCF(默认值:7000)
lowpass_filter_width (int, optional) – 确定低通滤波器宽度的整数,值越大滤波器越锐利。 (默认值:1)
upsample_filter_width (int, optional) – 确定上采样 NCCF 时滤波器宽度的整数。(默认值:5)
max_frames_latency (int, optional) – 允许音高跟踪在特征处理中引入的最大延迟帧数(仅当
frames_per_chunk > 0和simulate_first_pass_online=True时影响输出)(默认值:0)frames_per_chunk (int, optional) – 用于能量归一化的帧数。(默认值:0)
simulate_first_pass_online (bool, optional) – 如果为 true,该函数将输出与在线解码器在解码第一遍中看到的特征相对应的特征——而不是默认的最终版本特征。(默认值:False) 当
frames_per_chunk > 0时相关。recompute_frame (int, optional) – 仅与在线音高提取的兼容性相关。 一个非关键参数;在修订信号能量估计后,我们重新计算某些前向指针的帧。 当
frames_per_chunk > 0时相关。(默认值:500)snip_edges (bool, optional) – 如果此参数设置为 false,则不会裁剪靠近结束边缘的不完整帧, 因此帧数等于文件大小除以帧移。 这使得不同类型的特征具有相同数量的帧。(默认值:True)
- Returns
音高特征。形状:(batch, frames 2),其中最后一个维度对应音高和 NCCF。
- Return type
张量
- Tutorials using
compute_kaldi_pitch:
spectral_centroid¶
-
torchaudio.functional.spectral_centroid(waveform: torch.Tensor, sample_rate: int, pad: int, window: torch.Tensor, n_fft: int, hop_length: int, win_length: int) → torch.Tensor[source]¶ 沿时间轴计算每个通道的频谱质心。
频谱质心定义为频率值的加权平均值,权重为其幅度。
Multi-channel¶
psd¶
-
torchaudio.functional.psd(specgram: torch.Tensor, mask: Optional[torch.Tensor] = None, normalize: bool = True, eps: float = 1e-10) → torch.Tensor[source]¶ 计算跨通道功率谱密度 (PSD) 矩阵。
- Parameters
specgram (torch.Tensor) – 多通道复数频谱。 维度为 (…, channel, freq, time) 的张量。
mask (torch.Tensor 或 None, 可选) – 用于归一化的时频掩码。 维度为 (…, freq, time) 的张量。(默认值:
None)normalize (bool, optional) – 如果为
True,则沿时间维度对掩码进行归一化。(默认值:True)eps (float, optional) – 在掩码归一化中添加到分母的值。(默认值:
1e-15)
- Returns
输入频谱的复数PSD矩阵。 维度为 (…, freq, channel, channel) 的张量
- Return type
mvdr_weights_souden¶
-
torchaudio.functional.mvdr_weights_souden(psd_s: torch.Tensor, psd_n: torch.Tensor, reference_channel: Union[int, torch.Tensor], diagonal_loading: bool = True, diag_eps: float = 1e-07, eps: float = 1e-08) → torch.Tensor[source]¶ 计算最小方差无失真响应 (MVDR [6]) 波束形成权重 通过 Souden 等人 提出的方法 [7]。
给定目标语音的功率谱密度 (PSD) 矩阵 \(\bf{\Phi}_{\textbf{SS}}\)、噪声的 PSD 矩阵 \(\bf{\Phi}_{\textbf{NN}}\),以及表示参考通道的独热向量 \(\bf{u}\),该方法计算 MVDR 波束成形权重矩阵 \(\textbf{w}_{\text{MVDR}}\)。公式定义如下:
\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bf{\Phi}_{\textbf{SS}}}}(f)} {\text{Trace}({{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f) \bf{\Phi}_{\textbf{SS}}}(f))}}\bm{u} \]- Parameters
psd_s (torch.Tensor) – 目标语音的复数值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
psd_n (torch.Tensor) – 噪声的复值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
reference_channel (int 或 torch.Tensor) – 指定参考通道。 如果 dtype 为
int,则表示参考通道索引。 如果 dtype 为torch.Tensor,其形状为 (…, channel),其中channel维度 为 one-hot。diagonal_loading (bool, optional) – 如果为
True,则启用对psd_n应用对角加载。 (默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)eps (float, optional) – 在波束成形权重公式的分母中添加的值。 (默认值:
1e-8)
- Returns
维度为 (…, freq, channel) 的复数 MVDR 波束成形权重矩阵。
- Return type
mvdr_weights_rtf¶
-
torchaudio.functional.mvdr_weights_rtf(rtf: torch.Tensor, psd_n: torch.Tensor, reference_channel: Optional[Union[int, torch.Tensor]] = None, diagonal_loading: bool = True, diag_eps: float = 1e-07, eps: float = 1e-08) → torch.Tensor[source]¶ 根据噪声的相对传递函数 (RTF) 和功率谱密度 (PSD) 矩阵,计算最小方差无失真响应 (MVDR [6]) 波束成形权重。
给定目标语音的相对传递函数(RTF)矩阵或导向矢量 \(\bm{v}\)、噪声的功率谱密度(PSD)矩阵 \(\bf{\Phi}_{\textbf{NN}}\) 以及表示参考通道的独热向量 \(\bf{u}\),该方法计算 MVDR 波束成形权重矩阵 \(\textbf{w}_{\text{MVDR}}\)。公式定义如下:
\[\textbf{w}_{\text{MVDR}}(f) = \frac{{{\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)}} {{\bm{v}^{\mathsf{H}}}(f){\bf{\Phi}_{\textbf{NN}}^{-1}}(f){\bm{v}}(f)} \]其中 \((.)^{\mathsf{H}}\) 表示厄米共轭运算。
- Parameters
rtf (torch.Tensor) – 目标语音的复数值 RTF 向量。 维度为 (…, freq, channel) 的张量。
psd_n (torch.Tensor) – 噪声的复值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
reference_channel (int 或 torch.Tensor) – 指定参考通道。 如果 dtype 为
int,则表示参考通道索引。 如果 dtype 为torch.Tensor,其形状为 (…, channel),其中channel维度 为 one-hot。diagonal_loading (bool, optional) – 如果为
True,则启用对psd_n应用对角加载。 (默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)eps (float, optional) – 在波束成形权重公式的分母中添加的值。 (默认值:
1e-8)
- Returns
维度为 (…, freq, channel) 的复数 MVDR 波束成形权重矩阵。
- Return type
rtf_evd¶
-
torchaudio.functional.rtf_evd(psd_s: torch.Tensor) → torch.Tensor[source]¶ 通过特征值分解估计相对传递函数(RTF)或导向矢量。
- Parameters
psd_s (Tensor) – 目标语音的复数值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量
- Returns
目标语音的估计复值RTF。 维度为 (…, freq, channel) 的张量
- Return type
张量
- Tutorials using
rtf_evd:
rtf_power¶
-
torchaudio.functional.rtf_power(psd_s: torch.Tensor, psd_n: torch.Tensor, reference_channel: Union[int, torch.Tensor], n_iter: int = 3, diagonal_loading: bool = True, diag_eps: float = 1e-07) → torch.Tensor[source]¶ 通过功率法估计相对传递函数 (RTF) 或导向矢量。
- Parameters
psd_s (torch.Tensor) – 目标语音的复数值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
psd_n (torch.Tensor) – 噪声的复值功率谱密度 (PSD) 矩阵。 维度为 (…, freq, channel, channel) 的张量。
reference_channel (int 或 torch.Tensor) – 指定参考通道。 如果 dtype 为
int,则表示参考通道索引。 如果 dtype 为torch.Tensor,其形状为 (…, channel),其中channel维度 为 one-hot。diagonal_loading (bool, optional) – 如果为
True,则启用对psd_n应用对角加载。 (默认值:True)diag_eps (float, optional) – 用于对角加载的乘以单位矩阵的系数。 仅当
diagonal_loading设置为True时有效。(默认值:1e-7)
- Returns
目标语音的估计复值RTF。 维度为 (…, freq, channel) 的张量。
- Return type
- Tutorials using
rtf_power:
apply_beamforming¶
-
torchaudio.functional.apply_beamforming(beamform_weights: torch.Tensor, specgram: torch.Tensor) → torch.Tensor[source]¶ 将波束成形权重应用于多通道噪声频谱,以获得单通道增强频谱。
\[\hat{\textbf{S}}(f) = \textbf{w}_{\text{bf}}(f)^{\mathsf{H}} \textbf{Y}(f) \]其中 \(\textbf{w}_{\text{bf}}(f)\) 是第 \(f\) 个频率箱的波束成形权重, \(\textbf{Y}\) 是第 \(f\) 个频率箱的多通道频谱。
- Parameters
beamform_weights (Tensor) – 复数波束成形权重矩阵。 维度为 (…, freq, channel) 的张量
specgram (Tensor) – 多通道复值噪声频谱。 维度为 (…, channel, freq, time) 的张量
- Returns
- The single-channel complex-valued enhanced spectrum.
维度为 (…, freq, time) 的张量
- Return type
张量
损失¶
rnnt_loss¶
-
torchaudio.functional.rnnt_loss(logits: torch.Tensor, targets: torch.Tensor, logit_lengths: torch.Tensor, target_lengths: torch.Tensor, blank: int = - 1, clamp: float = - 1, reduction: str = 'mean')[source]¶ 计算来自基于循环神经网络的序列转导的RNN Transducer损失 [8]。
RNN Transducer 损失通过定义所有长度输出序列上的分布,并联合建模输入 - 输出和输出 - 输出依赖关系,扩展了 CTC 损失。
- Parameters
logits (Tensor) – 维度为 (batch, max seq length, max target length + 1, class) 的张量,包含来自 joiner 的输出
targets (Tensor) – 维度为 (batch, max target length) 的张量,包含经过零填充的目标值
logit_lengths (Tensor) – 维度为 (batch) 的张量,包含来自编码器的每个序列的长度
target_lengths (Tensor) – 维度为 (batch) 的张量,包含每个序列的目标长度
blank (int, optional) – 空白标签(默认值:
-1)clamp (float, optional) – 梯度截断(默认值:
-1)reduction (string, optional) – 指定应用于输出的归约方式:
'none'|'mean'|'sum'。(默认值:'mean')
- Returns
应用 reduction 选项后的损失。如果
reduction是'none',则大小为 (batch),否则为标量。- Return type
张量
指标¶
edit_distance¶
-
torchaudio.functional.edit_distance(seq1: collections.abc.Sequence, seq2: collections.abc.Sequence) → int[source]¶ 计算两个序列之间的词级编辑(Levenshtein)距离。
该函数计算允许删除、插入和替换的编辑距离。结果为一个整数。
对于大多数应用,两个输入序列应为相同类型。如果提供两个字符串,输出为这两个字符串之间的编辑距离(字符编辑距离)。如果提供两个字符串列表,输出为句子之间的编辑距离(词编辑距离)。用户可能希望根据参考序列的长度对输出进行归一化。
- Parameters
seq1 (Sequence) – 要比较的第一个序列。
seq2 (Sequence) – 要比较的第二个序列。
- Returns
第一个序列与第二个序列之间的距离。
- Return type
- Tutorials using
edit_distance:
参考文献¶
- 1
Julius O. Smith. 数字音频重采样主页“理想带限插值理论”部分。2020年9月。网址:https://ccrma.stanford.edu/~jos/resample/Theory_Ideal_Bandlimited_Interpolation.html。
- 2
Brian McFee, Colin Raffel, Dawen Liang, Daniel P.W. Ellis, Matt McVicar, Eric Battenberg, 和 Oriol Nieto。Librosa:使用 Python 进行音频和音乐信号分析。收录于 Kathryn Huff 和 James Bergstra 编辑的《第 14 届 Python 科学会议论文集》中,第 18 – 24 页。2015 年。doi:10.25080/Majora-7b98e3ed-003.
- 3
Nathanaël Perraudin, Peter Balazs, 和 Peter L. Søndergaard。一种快速的Griffin-Lim算法。发表于 2013 IEEE 信号处理在音频与声学中的应用研讨会,卷,1–4。2013。 doi:10.1109/WASPAA.2013.6701851。
- 4
D. Griffin 和 Jae Lim. 基于修正短时傅里叶变换的信号估计。收录于 ICASSP ‘83. IEEE 声学、语音与信号处理国际会议,第 8 卷,804–807 页。1983 年。doi:10.1109/ICASSP.1983.1172092。
- 5
Pegah Ghahremani, Bagher BabaAli, Daniel Povey, Korbinian Riedhammer, Jan Trmal, 和 Sanjeev Khudanpur. 一种针对自动语音识别优化的音高提取算法。收录于 2014 IEEE 国际声学、语音与信号处理会议 (ICASSP),卷号,第 2494–2498 页。2014 年。doi:10.1109/ICASSP.2014.6854049。
- 6(1,2)
Jack Capon。高分辨率频率-波数谱分析。IEEE proceedings, 57(8):1408–1418, 1969。
- 7
Mehrez Souden, Jacob Benesty, 和 Sofiene Affes. 关于噪声抑制的最优频域多通道线性滤波. 在 IEEE音频、语音和语言处理汇刊, 第18卷, 260–276页. IEEE, 2009.
- 8
Alex Graves. 使用循环神经网络进行序列转换。2012. arXiv:1211.3711.