注意
单击此处下载完整的示例代码
使用 NVENC 加速视频编码¶
作者: Moto Hira
本教程介绍如何使用 NVIDIA 的硬件视频编码器 (NVENC) 替换为 TorchAudio,以及它如何提高视频编码的性能。
注意
大多数现代 GPU 同时具有硬件解码器和编码器,但有些 GPU 具有 A100 和 H100 等高端 GPU 没有硬件编码器。 请参阅以下内容了解可用性和 格式覆盖率。https://developer.nvidia.com/video-encode-and-decode-gpu-support-matrix-new
尝试在这些 GPU 上使用 HW 编码器失败,并显示错误
类似 的消息。
您可以使用Generic error in an external librarytorchaudio.utils.ffmpeg_utils.set_log_level()查看更多
沿途发布的详细错误消息。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
import io
import time
import matplotlib.pyplot as plt
from IPython.display import Video
from torchaudio.io import StreamReader, StreamWriter
2.4.0
2.4.0
检查先决条件¶
首先,我们检查 TorchAudio 是否正确检测 FFmpeg 库 支持硬件解码器/编码器。
from torchaudio.utils import ffmpeg_utils
FFmpeg Library versions:
libavcodec: 60.3.100
libavdevice: 60.1.100
libavfilter: 9.3.100
libavformat: 60.3.100
libavutil: 58.2.100
Available NVENC Encoders:
- av1_nvenc
- h264_nvenc
- hevc_nvenc
print("Avaialbe GPU:")
print(torch.cuda.get_device_properties(0))
Avaialbe GPU:
_CudaDeviceProperties(name='NVIDIA A10G', major=8, minor=6, total_memory=22502MB, multi_processor_count=80)
我们使用以下 helper 函数生成测试帧数据。 合成视频生成的详细信息请参考 StreamReader Advanced 使用方法。
def get_data(height, width, format="yuv444p", frame_rate=30000 / 1001, duration=4):
src = f"testsrc2=rate={frame_rate}:size={width}x{height}:duration={duration}"
s = StreamReader(src=src, format="lavfi")
s.add_basic_video_stream(-1, format=format)
s.process_all_packets()
(video,) = s.pop_chunks()
return video
使用 NVENC 对视频进行编码¶
要使用 HW 视频编码器,您需要在
通过提供选项来定义输出视频流。encoderadd_video_stream()
pict_config = {
"height": 360,
"width": 640,
"frame_rate": 30000 / 1001,
"format": "yuv444p",
}
frame_data = get_data(**pict_config)
w = StreamWriter(io.BytesIO(), format="mp4")
w.add_video_stream(**pict_config, encoder="h264_nvenc", encoder_format="yuv444p")
with w.open():
w.write_video_chunk(0, frame_data)
与 HW 解码器类似,默认情况下,编码器需要帧
data 添加到 CPU 内存中。要从 CUDA 内存发送数据,您需要
指定选项。hw_accel
buffer = io.BytesIO()
w = StreamWriter(buffer, format="mp4")
w.add_video_stream(**pict_config, encoder="h264_nvenc", encoder_format="yuv444p", hw_accel="cuda:0")
with w.open():
w.write_video_chunk(0, frame_data.to(torch.device("cuda:0")))
buffer.seek(0)
video_cuda = buffer.read()
Video(video_cuda, embed=True, mimetype="video/mp4")
使用 StreamWriter 对 NVENC 进行基准测试¶
现在我们比较软件编码器和硬件的性能 编码器。
与 NVDEC 中的基准测试类似,我们处理不同 resolution 的 Resolution,并测量对它们进行编码所需的时间。
我们还测量了结果视频文件的大小。
以下函数对给定的帧进行编码并测量时间 它需要编码和结果视频数据的大小。
def test_encode(data, encoder, width, height, hw_accel=None, **config):
assert data.is_cuda
buffer = io.BytesIO()
s = StreamWriter(buffer, format="mp4")
s.add_video_stream(encoder=encoder, width=width, height=height, hw_accel=hw_accel, **config)
with s.open():
t0 = time.monotonic()
if hw_accel is None:
data = data.to("cpu")
s.write_video_chunk(0, data)
elapsed = time.monotonic() - t0
size = buffer.tell()
fps = len(data) / elapsed
print(f" - Processed {len(data)} frames in {elapsed:.2f} seconds. ({fps:.2f} fps)")
print(f" - Encoded data size: {size} bytes")
return elapsed, size
我们针对以下配置进行测试
线程数为 1、4、8 的软件编码器
带和不带选项的硬件编码器。
hw_accel
def run_tests(height, width, duration=4):
# Generate the test data
print(f"Testing resolution: {width}x{height}")
pict_config = {
"height": height,
"width": width,
"frame_rate": 30000 / 1001,
"format": "yuv444p",
}
data = get_data(**pict_config, duration=duration)
data = data.to(torch.device("cuda:0"))
times = []
sizes = []
# Test software encoding
encoder_config = {
"encoder": "libx264",
"encoder_format": "yuv444p",
}
for i, num_threads in enumerate([1, 4, 8]):
print(f"* Software Encoder (num_threads={num_threads})")
time_, size = test_encode(
data,
encoder_option={"threads": str(num_threads)},
**pict_config,
**encoder_config,
)
times.append(time_)
if i == 0:
sizes.append(size)
# Test hardware encoding
encoder_config = {
"encoder": "h264_nvenc",
"encoder_format": "yuv444p",
"encoder_option": {"gpu": "0"},
}
for i, hw_accel in enumerate([None, "cuda"]):
print(f"* Hardware Encoder {'(CUDA frames)' if hw_accel else ''}")
time_, size = test_encode(
data,
**pict_config,
**encoder_config,
hw_accel=hw_accel,
)
times.append(time_)
if i == 0:
sizes.append(size)
return times, sizes
我们更改视频的分辨率,以查看这些测量效果如何 改变。
360P¶
Testing resolution: 640x360
* Software Encoder (num_threads=1)
- Processed 120 frames in 0.66 seconds. (181.40 fps)
- Encoded data size: 381331 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 0.24 seconds. (504.44 fps)
- Encoded data size: 381307 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 0.19 seconds. (633.77 fps)
- Encoded data size: 390689 bytes
* Hardware Encoder
- Processed 120 frames in 0.05 seconds. (2246.30 fps)
- Encoded data size: 1262979 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.05 seconds. (2587.23 fps)
- Encoded data size: 1262979 bytes
720点¶
Testing resolution: 1280x720
* Software Encoder (num_threads=1)
- Processed 120 frames in 2.38 seconds. (50.52 fps)
- Encoded data size: 1335451 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 0.85 seconds. (141.71 fps)
- Encoded data size: 1336418 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 0.73 seconds. (165.46 fps)
- Encoded data size: 1344063 bytes
* Hardware Encoder
- Processed 120 frames in 0.26 seconds. (467.74 fps)
- Encoded data size: 1358969 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.15 seconds. (801.83 fps)
- Encoded data size: 1358969 bytes
1080 点¶
Testing resolution: 1920x1080
* Software Encoder (num_threads=1)
- Processed 120 frames in 4.84 seconds. (24.82 fps)
- Encoded data size: 2678241 bytes
* Software Encoder (num_threads=4)
- Processed 120 frames in 1.79 seconds. (67.18 fps)
- Encoded data size: 2682028 bytes
* Software Encoder (num_threads=8)
- Processed 120 frames in 1.64 seconds. (73.14 fps)
- Encoded data size: 2685086 bytes
* Hardware Encoder
- Processed 120 frames in 0.56 seconds. (213.73 fps)
- Encoded data size: 1705900 bytes
* Hardware Encoder (CUDA frames)
- Processed 120 frames in 0.32 seconds. (370.99 fps)
- Encoded data size: 1705900 bytes
现在我们绘制结果。
def plot():
fig, axes = plt.subplots(2, 1, sharex=True, figsize=[9.6, 7.2])
for items in zip(time_360, time_720, time_1080, "ov^X+"):
axes[0].plot(items[:-1], marker=items[-1])
axes[0].grid(axis="both")
axes[0].set_xticks([0, 1, 2], ["360p", "720p", "1080p"], visible=True)
axes[0].tick_params(labeltop=False)
axes[0].legend(
[
"Software Encoding (threads=1)",
"Software Encoding (threads=4)",
"Software Encoding (threads=8)",
"Hardware Encoding (CPU Tensor)",
"Hardware Encoding (CUDA Tensor)",
]
)
axes[0].set_title("Time to encode videos with different resolutions")
axes[0].set_ylabel("Time [s]")
for items in zip(size_360, size_720, size_1080, "v^"):
axes[1].plot(items[:-1], marker=items[-1])
axes[1].grid(axis="both")
axes[1].set_xticks([0, 1, 2], ["360p", "720p", "1080p"])
axes[1].set_ylabel("The encoded size [bytes]")
axes[1].set_title("The size of encoded videos")
axes[1].legend(
[
"Software Encoding",
"Hardware Encoding",
]
)
plt.tight_layout()
plot()
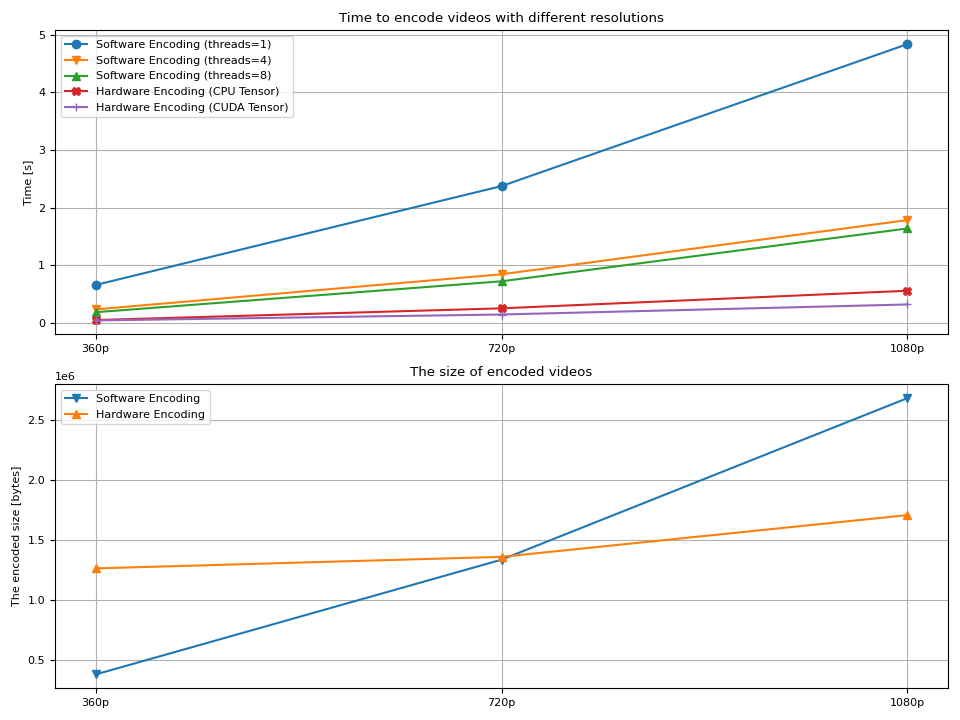
结果¶
我们观察到几件事;
编码视频的时间随着分辨率的增加而增加。
在软件编码的情况下,增加线程数 有助于减少解码时间。
额外线程的增益在 8 左右减少。
硬件编码通常比软件编码更快。
使用 不会提高编码本身的速度 一样多。
hw_accel生成的视频的大小会随着分辨率的增加而增加 较大。
硬件编码器以较大的分辨率生成较小的视频文件。
最后一点对作者来说有些奇怪(他不是 视频制作专家。 人们常说,硬件解码器会产生更大的视频 与软件编码器相比。 有人说软件编码器允许对 encoding 配置,因此生成的视频更优化。 同时,硬件编码器针对性能进行了优化,因此 对质量和二进制大小没有提供太多控制。
质量抽查¶
那么,使用硬件编码器制作的视频质量如何呢? 对高分辨率视频的快速抽查发现他们有 在更高分辨率下,伪像更明显。 这可能是二进制文件大小较小的原因。(意思是, 它没有分配足够的位来产生高质量的输出。
下图是使用硬件编码的视频的原始帧 编码。
360P¶

720点¶

1080 点¶

我们可以看到,在更高的分辨率下有更多的伪影,这 都很明显。
也许可以使用参数来减少这些。
我们没有尝试,但如果您尝试并找到更好的质量
设置,请随时告诉我们。;)encoder_options
脚本总运行时间:(0 分 22.418 秒)