ExecuTorch Llama iOS 演示应用¶
[更新 - 10/24] 我们已在 XNNPACK 后端的演示应用中添加了对运行量化 Llama 3.2 1B/3B 模型的支持。我们目前支持使用 SpinQuant 和 QAT+LoRA 量化方法进行推理。
我们很高兴地宣布,全新升级的 iOS 演示应用现已上线,并包含许多新功能,以提供更直观、更流畅的用户体验,特别是在聊天用例方面!该应用的主要目标是展示如何轻松地将 ExecuTorch 集成到 iOS 演示应用中,并演示 ExecuTorch 和 Llama 模型所提供的诸多功能。
该应用程序是一个有价值的资源,可激发你的创造力,并提供基础代码,你可以根据自己的具体用例进行定制和调整。
请立即深入探索我们的演示应用!我们期待收到您的任何反馈,并且非常期待看到您富有创意的想法。
核心概念¶
从这个演示应用中,你将学习到许多关键概念,例如:
如何准备 Llama 模型、构建 ExecuTorch 库,并在委托之间执行模型推理
通过 Swift Package Manager 暴露 ExecuTorch 库
熟悉当前 ExecuTorch 应用接口功能
目标是让您了解 ExecuTorch 提供的支持类型,并能够自如地将其用于您的使用场景。
支持的模型¶
总体而言,此应用支持的模型为(因委托而异):
Llama 3.2 量化 1B/3B
Llama 3.2 1B/3B 在 BF16 中
Llama 3.1 8B
Llama 3 8B
Llama 2 7B
Llava 1.5(仅 XNNPACK)
构建应用程序¶
首先需要注意的是,目前 ExecuTorch 支持多个委托(delegates)。一旦您确定了自己选择的委托,选择 README 链接以获取完整的端到端指导,用于环境设置,将模型导出以构建 ExecuTorch 库和应用,以便在设备上运行:
委托 |
资源 |
|---|---|
XNNPACK(基于CPU的库) |
|
MPS(Metal Performance Shader) |
如何使用该应用¶
本节将介绍使用该应用的主要步骤,并提供一个 ExecuTorch API 的代码片段。
Swift Package Manager¶
ExecuTorch runtime 作为 Swift 包分发,提供一些 .xcframework 作为预构建的二进制目标。 Xcode 在首次运行时会下载并缓存该包,这将花费一些时间。
注意:如果您遇到与包依赖相关的问题,请完全退出 Xcode,删除整个 executorch 仓库,通过在终端运行以下命令清理缓存,然后重新克隆仓库。
rm -rf \
~/Library/org.swift.swiftpm \
~/Library/Caches/org.swift.swiftpm \
~/Library/Caches/com.apple.dt.Xcode \
~/Library/Developer/Xcode/DerivedData
将你的二进制文件与 ExecuTorch 运行时以及导出的机器学习模型所使用的任何后端或内核进行链接。建议将核心运行时直接链接到使用 ExecuTorch 的组件,并将内核和后端链接到主应用程序目标。
注意:要访问日志,请链接 ExecuTorch 运行时的 Debug 版本,即 executorch_debug 框架。为了获得最佳性能,请务必链接交付物的 Release 版本(不带 _debug 后缀的版本),这些版本已移除所有日志开销。
有关在Apple平台上集成和运行ExecuTorch的更多详情,请查看此链接。
XCode¶
打开 XCode 并选择“打开现有项目”以打开
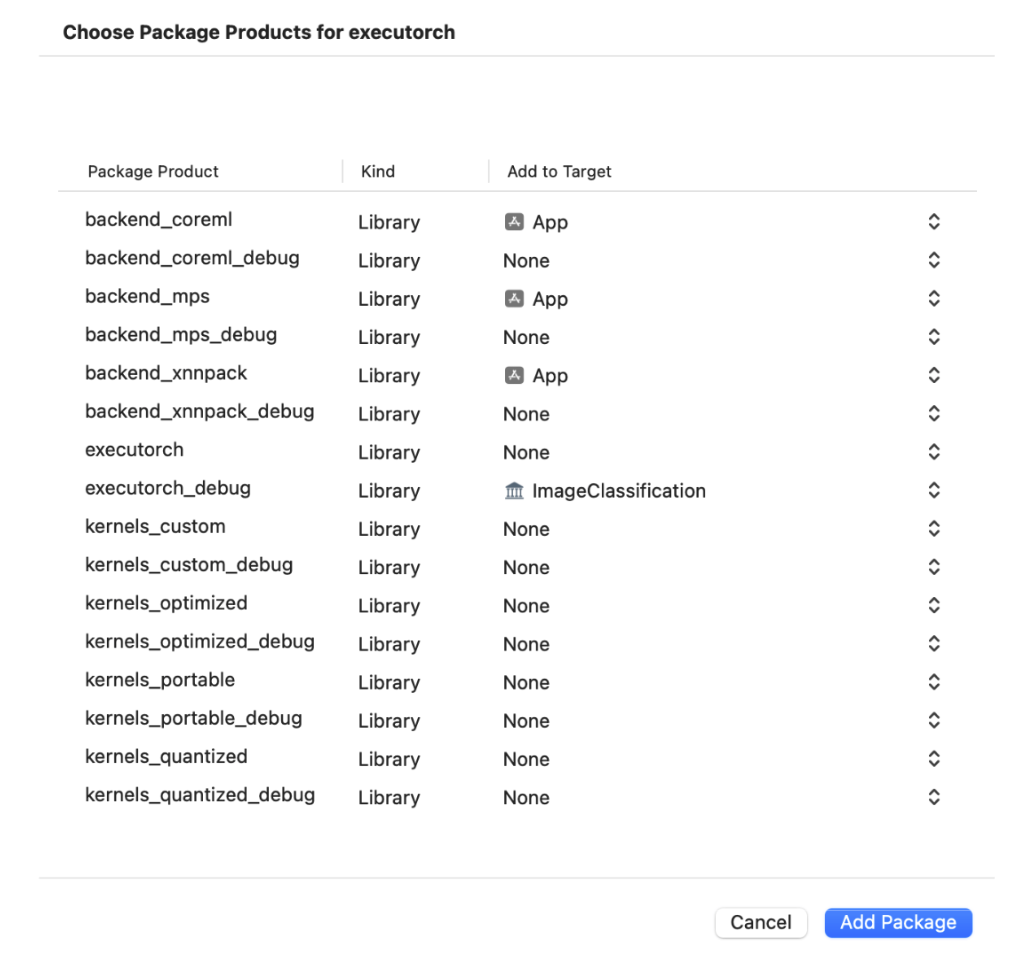
examples/demo-apps/apple_ios/LLama。确保已正确安装 ExecuTorch 包的依赖项,然后选择应将哪个 ExecuTorch 框架链接到哪个目标。

运行应用。这将构建并在手机上启动该应用。
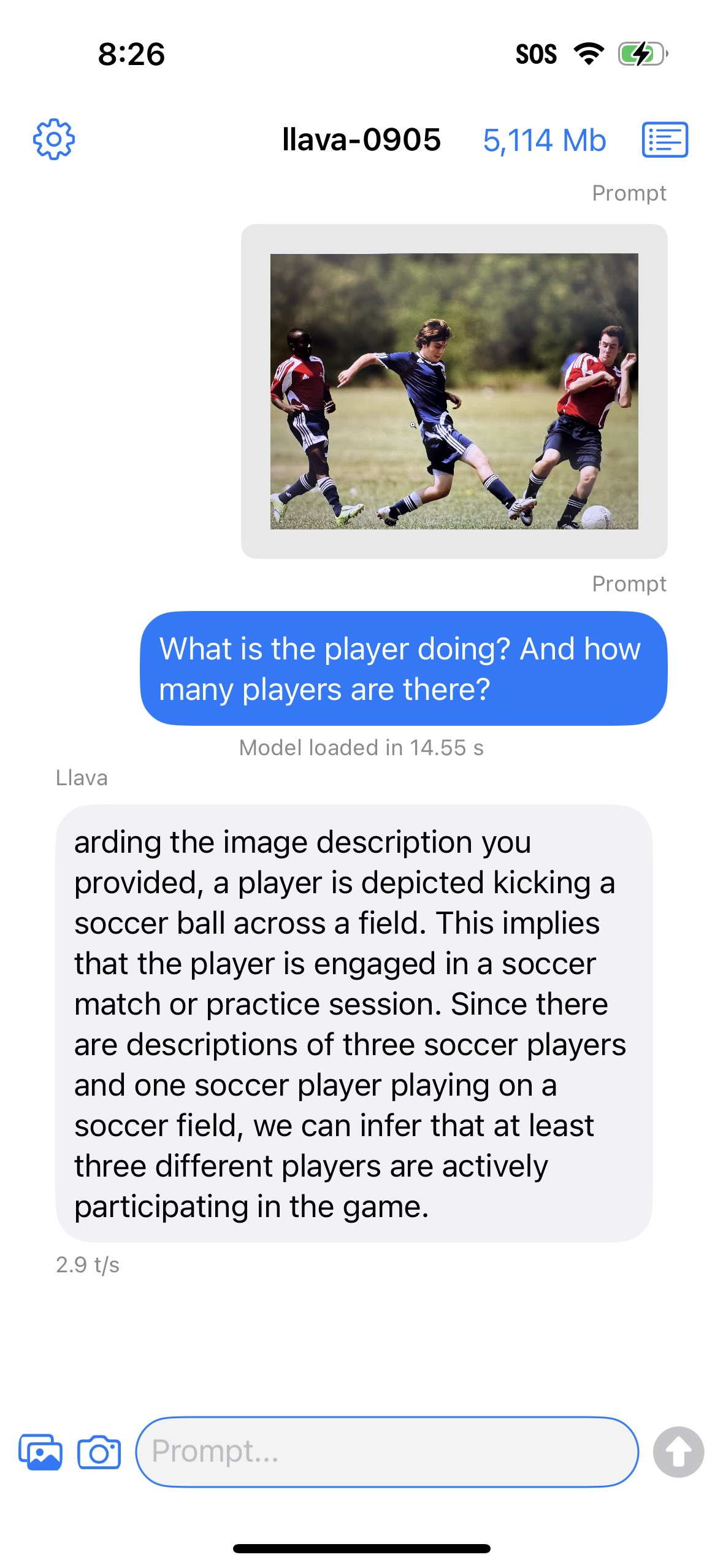
在应用界面中选择一个模型和分词器,输入提示并点击箭头按钮。
将模型复制到模拟器¶
将模型和分词器文件拖放到模拟器窗口中,并将其保存到 iLLaMA 文件夹内的任意位置。
在应用对话框中选择文件,输入提示词,然后点击向上箭头按钮。
将模型复制到设备¶
用数据线连接设备,并在访达中打开其内容。
导航至“文件”选项卡,将模型和分词器文件拖放到 iLLaMA 文件夹中。
等待文件复制完成。
如果应用成功在您的设备上运行,您应该看到如下内容:

对于 Llava 1.5 模型,您可以在输入提示并点击发送按钮之前,先选择一张图片(通过图像/相机选择器按钮)。