在 Xtensa HiFi4 DSP 上构建和运行 ExecuTorch¶
在本教程中,我们将引导您完成为 Xtensa HiFi4 DSP 构建 ExecuTorch 并在其上运行简单模型的过程。
Cadence 既是硬件和软件供应商,也为许多计算工作负载提供解决方案,包括在功率受限的嵌入式设备上运行。Xtensa HiFi4 DSP 是一款数字信号处理器 (DSP),针对运行基于音频的神经网络进行了优化,例如唤醒词检测、自动语音识别 (ASR) 等。
除了芯片之外,HiFi4 神经网络库 (nnlib) 还提供了一组优化的 NN 处理中常用的库函数,我们在此示例中使用这些函数来演示如何加速常见操作。
除了能够在 Xtensa HiFi4 DSP 上运行之外,本教程的另一个目标是演示 ExecuTorch 的便携性及其在 Xtensa HiFi4 DSP 等低功耗嵌入式设备上运行的能力。此工作流程不需要任何委托,它使用自定义运算符和编译器传递来增强模型,使其更适合在 Xtensa HiFi4 DSP 上运行。自定义量化器用于将激活和权重表示为 ,而不是 ,并调用适当的运算符。最后,使用 Xtensa 内联函数优化的自定义内核可提供运行时加速。uint8float
在本教程中,您将学习如何使用针对 Xtensa HiFi4 DSP 的线性运算导出量化模型。
您还将学习如何编译和部署 ExecuTorch 运行时,以及在 Xtensa HiFi4 DSP 上运行上一步中生成的量化模型所需的内核。
注意
本教程的 linux 部分已在 Ubuntu 22.04 LTS 上设计和测试,需要 glibc 2.34。解决方法可用于其他发行版,但本教程不会介绍。
先决条件(硬件和软件)¶
为了能够在 Xtensa HiFi4 DSP 上成功构建和运行 ExecuTorch,您需要以下硬件和软件组件。
软件¶
x86-64 Linux 系统(用于编译 DSP 二进制文件)
-
此 IDE 在包括 MacOS 在内的多个平台上受支持。您可以在任何支持的平台上使用它,因为您只会使用它来刷写带有您将在本教程后面构建的 DSP 映像的板。
-
需要使用固件映像刷新板。您可以在安装MCUXpresso IDE的同一平台上安装它。
注意:根据 NXP 板的版本,可能会安装 JLink 以外的其他探针。在任何情况下,刷写都是使用 MCUXpresso IDE 以类似的方式完成的。
-
将此 SDK 下载到您的 Linux 计算机,将其解压缩并记下存储它的路径。您稍后会用到它。
-
将此文件下载到您的 Linux 计算机。这是为 HiFi4 DSP 构建 ExecuTorch 所必需的。
对于具有优化内核的情况,请使用 nnlib 存储库。
设置 Developer Environment¶
步骤 1.为了能够成功安装上面指定的所有软件组件,用户需要完成下面链接的 NXP 教程。尽管本教程本身介绍了 Windows 设置,但大多数步骤也转换为 Linux 安装。
注意
在继续下一部分之前,用户应该能够成功刷写上述教程中dsp_mu_polling_cm33示例应用程序,并注意到 UART 控制台上的输出指示 Cortex-M33 和 HiFi4 DSP 正在相互通信。
步骤 2。确保您已完成本页顶部链接的 ExecuTorch 设置教程。
工作树描述¶
工作树为:
executorch
├── backends
│ └── cadence
│ ├── aot
│ ├── ops_registration
│ ├── tests
│ ├── utils
│ ├── hifi
│ │ ├── kernels
│ │ ├── operators
│ │ └── third-party
│ │ └── hifi4-nnlib
│ └── [other cadence DSP families]
│ ├── kernels
│ ├── operators
│ └── third-party
│ └── [any required lib]
└── examples
└── cadence
├── models
└── operators
AoT(提前)组件:
AoT 文件夹包含将模型导出到 ExecuTorch 文件所需的所有 python 脚本和函数。在我们的例子中,export_example.py 是一个 API,它采用模型 (nn.Module) 和代表性输入,并通过量化器(从 quantizer.py)运行它。然后,一些编译器传递(也在 quantizer.py 中定义)将 Operator 替换为在芯片上支持和优化的自定义 Operator。任何计算事物所需的运算符都应该在 ops_registrations.py 中定义,并在其他文件夹中有相应的实现。.pte
运算符:
operators 文件夹包含两种类型的运算符:ExecuTorch 可移植库中的现有运算符和定义自定义计算的新运算符。前者只是简单地将 Operator 分派给相关的 ExecuTorch 实现,而后者充当接口,设置自定义内核计算输出所需的一切。
内核:
kernels 文件夹包含将在 HiFi4 芯片上运行的优化内核。它们使用 Xtensa 内在函数以低功耗提供高性能。
建¶
在此步骤中,您将从不同的模型生成 ExecuTorch 程序。然后,您将在运行时构建步骤中使用此 Program(文件)将此 Program 烘焙到 DSP 映像中。.pte
简单型号:
第一个简单模型用于测试本教程的所有组件是否正常工作,并且只执行 add 操作。生成的文件称为 。add.pte
cd executorch
python3 -m examples.portable.scripts.export --model_name="add"
量化算子:
另一个更复杂的模型是自定义运算符,包括:
在这两种情况下,生成的文件都称为 .CadenceDemoModel.pte
cd executorch
python3 -m examples.cadence.operators.quantized_<linear,conv1d>_op
小模型:RNNT 预测变量:
torchaudio RNNT 转换器模型是一种自动语音识别 (ASR) 模型,由三个不同的子模型组成:编码器、预测器和连接器。 预测器是一系列基本运算(嵌入、ReLU、线性、层范数),可以使用以下方法导出:
cd executorch
python3 -m examples.cadence.models.rnnt_predictor
生成的文件称为 。CadenceDemoModel.pte
运行¶
构建 DSP 固件映像在此步骤中,您将构建 DSP 固件映像,该映像由示例 ExecuTorch 运行程序以及上一步生成的程序组成。此图像加载到 DSP 时,将穿过此程序组成的模型。
步骤 1.配置所需的环境变量,以指向您在上一步中安装的 Xtensa 工具链。需要设置的三个环境变量包括:
# Directory in which the Xtensa toolchain was installed
export XTENSA_TOOLCHAIN=/home/user_name/cadence/XtDevTools/install/tools
# The version of the toolchain that was installed. This is essentially the name of the directory
# that is present in the XTENSA_TOOLCHAIN directory from above.
export TOOLCHAIN_VER=RI-2021.8-linux
# The Xtensa core that you're targeting.
export XTENSA_CORE=nxp_rt600_RI2021_8_newlib
步骤 2。使用 克隆 nnlib 存储库,其中包含针对 HiFi4 DSP 的优化内核和基元。git clone git@github.com:foss-xtensa/nnlib-hifi4.git
步骤 3。运行 CMake 构建。 为了运行 CMake 构建,您需要以下路径:
在上一步中生成的 Program
NXP SDK 根目录的路径。这应该已经在 设置开发人员环境 部分中安装了。这是包含 boards、components、devices 等文件夹的目录。
cd executorch
rm -rf cmake-out
# prebuild and install executorch library
cmake -DCMAKE_TOOLCHAIN_FILE=<path_to_executorch>/backends/cadence/cadence.cmake \
-DCMAKE_INSTALL_PREFIX=cmake-out \
-DCMAKE_BUILD_TYPE=Debug \
-DPYTHON_EXECUTABLE=python3 \
-DEXECUTORCH_BUILD_EXTENSION_RUNNER_UTIL=ON \
-DEXECUTORCH_BUILD_HOST_TARGETS=ON \
-DEXECUTORCH_BUILD_EXECUTOR_RUNNER=OFF \
-DEXECUTORCH_BUILD_PTHREADPOOL=OFF \
-DEXECUTORCH_BUILD_CPUINFO=OFF \
-DEXECUTORCH_BUILD_FLATC=OFF \
-DFLATC_EXECUTABLE="$(which flatc)" \
-Bcmake-out .
cmake --build cmake-out -j<num_cores> --target install --config Debug
# build cadence runner
cmake -DCMAKE_BUILD_TYPE=Debug \
-DCMAKE_TOOLCHAIN_FILE=<path_to_executorch>/examples/backends/cadence.cmake \
-DCMAKE_PREFIX_PATH=<path_to_executorch>/cmake-out \
-DMODEL_PATH=<path_to_program_file_generated_in_previous_step> \
-DNXP_SDK_ROOT_DIR=<path_to_nxp_sdk_root> -DEXECUTORCH_BUILD_FLATC=0 \
-DFLATC_EXECUTABLE="$(which flatc)" \
-DNN_LIB_BASE_DIR=<path_to_nnlib_cloned_in_step_2> \
-Bcmake-out/examples/cadence \
examples/cadence
cmake --build cmake-out/examples/cadence -j8 -t cadence_executorch_example
成功运行上述步骤后,您应该会在它们的 CMake 输出目录中看到两个二进制文件。
> ls cmake-xt/*.bin
cmake-xt/dsp_data_release.bin cmake-xt/dsp_text_release.bin
在设备上部署和运行¶
步骤 1.现在,您将获取上一步生成的 DSP 二进制映像,并将其复制到在设置开发人员环境部分创建的 NXP 工作区中。将 DSP 图像复制到下图中突出显示的部分。dsp_binary
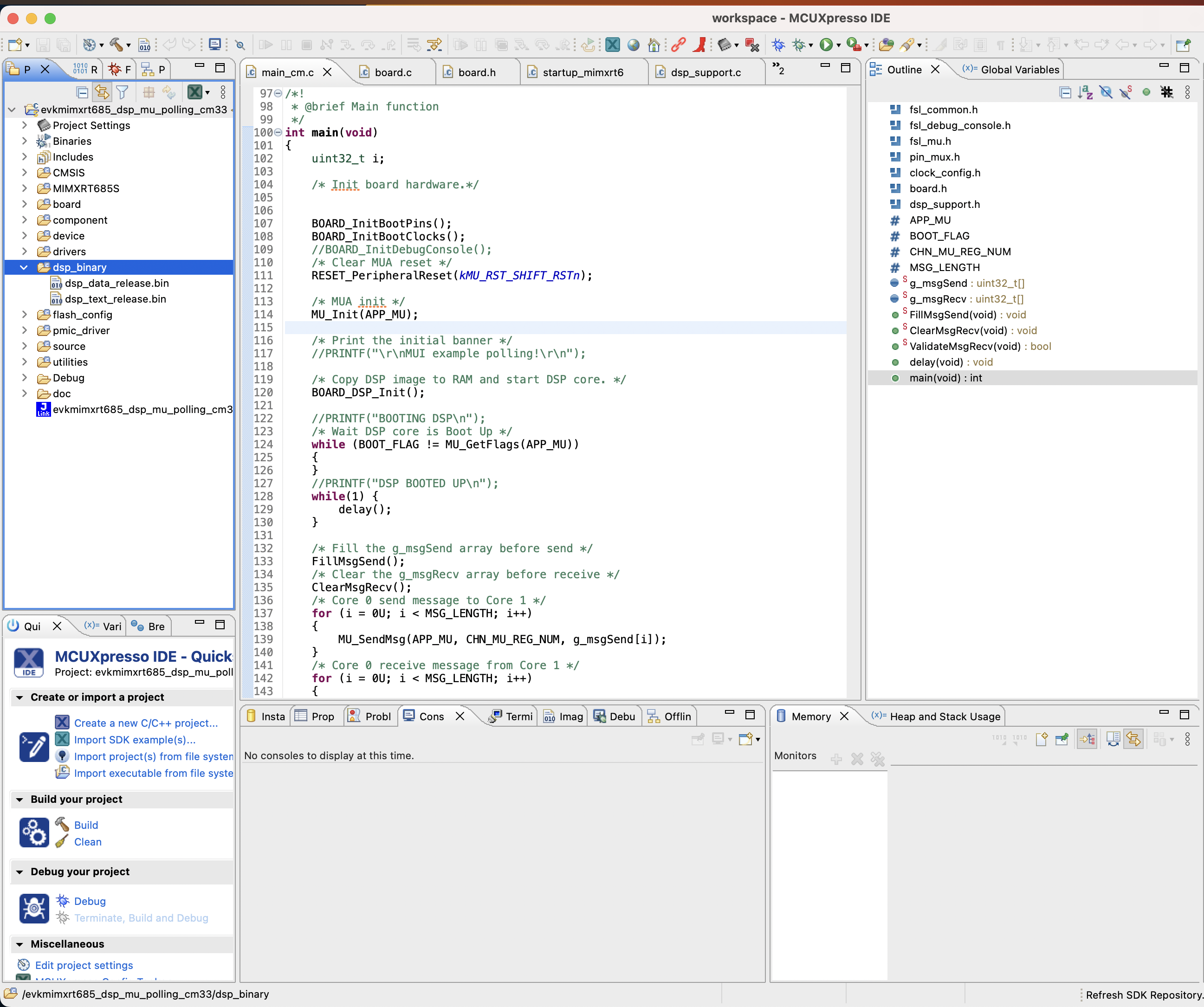
注意
只要二进制文件是在Linux上使用Xtensa工具链构建的,就只能使用MCUXpresso IDE来刷新电路板并在芯片上运行,该IDE适用于所有平台(Linux、MacOS、Windows)。
步骤 2。清洁您的工作空间
步骤 3。单击 Debug your Project,这将使用二进制文件刷写板。
在连接到开发板的 UART 控制台上(默认波特率为 115200),您应该会看到类似于以下内容的输出:
> screen /dev/tty.usbmodem0007288234991 115200
Executed model
Model executed successfully.
First 20 elements of output 0
0.165528 0.331055 ...