torchaudio.pipelines¶
pipelines 子包包含用于访问预训练权重模型的 API,以及与这些预训练权重相关的信息和辅助函数。
wav2vec 2.0 / HuBERT - 表示学习¶
-
class
torchaudio.pipelines.Wav2Vec2Bundle[source]¶ 用于捆绑关联信息以使用预训练 Wav2Vec2Model 的数据类。
此类提供用于实例化预训练模型的接口,以及检索预训练权重和与该模型配合使用的附加数据所需的信息。
Torchaudio 库会实例化此类对象,每个对象代表一个不同的预训练模型。客户端代码应通过这些实例访问预训练模型。
请参阅下方了解用法和可用值。
- Example - Feature Extraction
>>> import torchaudio >>> >>> bundle = torchaudio.pipelines.HUBERT_BASE >>> >>> # Build the model and load pretrained weight. >>> model = bundle.get_model() Downloading: 100%|███████████████████████████████| 360M/360M [00:06<00:00, 60.6MB/s] >>> >>> # Resample audio to the expected sampling rate >>> waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate) >>> >>> # Extract acoustic features >>> features, _ = model.extract_features(waveform)
-
get_model(self, *, dl_kwargs=None) → torchaudio.models.Wav2Vec2Model[source]¶ 构建模型并加载预训练权重。
权重文件已从互联网下载并缓存,与
torch.hub.load_state_dict_from_url()- Parameters
dl_kwargs (关键字参数字典) – 传递给
torch.hub.load_state_dict_from_url()。
WAV2VEC2_BASE¶
WAV2VEC2_LARGE¶
WAV2VEC2_LARGE_LV60K¶
WAV2VEC2_XLSR53¶
HUBERT_BASE¶
HUBERT_LARGE¶
wav2vec 2.0 / HuBERT - 微调后的自动语音识别¶
Wav2Vec2ASRBundle¶
-
class
torchaudio.pipelines.Wav2Vec2ASRBundle[source]¶ 用于捆绑关联信息以使用预训练 Wav2Vec2Model 的数据类。
此类提供用于实例化预训练模型的接口,以及检索预训练权重和与该模型配合使用的附加数据所需的信息。
Torchaudio 库会实例化此类对象,每个对象代表一个不同的预训练模型。客户端代码应通过这些实例访问预训练模型。
请参阅下方了解用法和可用值。
- Example - ASR
>>> import torchaudio >>> >>> bundle = torchaudio.pipelines.HUBERT_ASR_LARGE >>> >>> # Build the model and load pretrained weight. >>> model = bundle.get_model() Downloading: 100%|███████████████████████████████| 1.18G/1.18G [00:17<00:00, 73.8MB/s] >>> >>> # Check the corresponding labels of the output. >>> labels = bundle.get_labels() >>> print(labels) ('<s>', '<pad>', '</s>', '<unk>', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z') >>> >>> # Resample audio to the expected sampling rate >>> waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate) >>> >>> # Infer the label probability distribution >>> emissions, _ = model(waveform) >>> >>> # Pass emission to decoder >>> # `ctc_decode` is for illustration purpose only >>> transcripts = ctc_decode(emissions, labels)
-
get_model(self, *, dl_kwargs=None) → torchaudio.models.Wav2Vec2Model¶ 构建模型并加载预训练权重。
权重文件已从互联网下载并缓存,与
torch.hub.load_state_dict_from_url()- Parameters
dl_kwargs (关键字参数字典) – 传递给
torch.hub.load_state_dict_from_url()。
-
get_labels(*, bos: str = '<s>', pad: str = '<pad>', eos: str = '</s>', unk: str = '<unk>') → Tuple[str][source]¶ 输出类别标签(仅适用于微调后的模型包)
前四个标记分别是 BOS、填充、EOS 和 UNK 标记,它们可以进行自定义。
- Parameters
- Returns
对于在 ASR 上微调的模型,返回表示输出类别标签的字符串元组。
- Return type
Tuple[str]
- Example
>>> import torchaudio >>> torchaudio.models.HUBERT_ASR_LARGE.get_labels() ('<s>', '<pad>', '</s>', '<unk>', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')

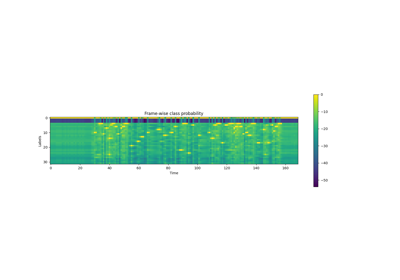
WAV2VEC2_ASR_BASE_10M¶
-
torchaudio.pipelines.WAV2VEC2_ASR_BASE_10M¶ 构建带有额外线性模块的“基础”wav2vec2 模型
使用来自 LibriSpeech 数据集的 960 小时未标注音频进行预训练 [1] (包括“train-clean-100”、“train-clean-360”和“train-other-500”),并 在来自 Libri-Light 数据集的 10 分钟已转录音频上针对 ASR 进行了微调 [3] (“train-10min”子集)。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_BASE_100H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_BASE_100H¶ 构建带有额外线性模块的“基础”wav2vec2 模型
在来自 LibriSpeech 数据集 [1] 的 960 小时无标签音频上进行预训练(“train-clean-100”、“train-clean-360”和“train-other-500”的组合),并在来自“train-clean-100”子集的 100 小时转录音频上针对 ASR 进行微调。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_BASE_960H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H¶ 构建带有额外线性模块的“基础”wav2vec2 模型
在来自 LibriSpeech 数据集 [1] 的 960 小时无标签音频上进行预训练(“train-clean-100”、“train-clean-360”和“train-other-500”的组合),并在带有相应转录文本的相同音频上针对 ASR 进行微调。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_LARGE_10M¶
-
torchaudio.pipelines.WAV2VEC2_ASR_LARGE_10M¶ 构建带有额外线性模块的“大型”wav2vec2 模型
使用来自 LibriSpeech 数据集的 960 小时未标注音频进行预训练 [1] (包括“train-clean-100”、“train-clean-360”和“train-other-500”),并 在来自 Libri-Light 数据集的 10 分钟已转录音频上针对 ASR 进行了微调 [3] (“train-10min”子集)。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_LARGE_100H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_LARGE_100H¶ 构建带有额外线性模块的“大型”wav2vec2 模型
在来自 LibriSpeech 数据集 [1] 的 960 小时无标签音频上进行预训练(“train-clean-100”、“train-clean-360”和“train-other-500”的组合),并在来自同一数据集(“train-clean-100”子集)的 100 小时转录音频上针对 ASR 进行微调。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_LARGE_960H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_LARGE_960H¶ 构建带有额外线性模块的“大型”wav2vec2 模型
在来自 LibriSpeech 数据集 [1] 的 960 小时无标签音频上进行预训练(“train-clean-100”、“train-clean-360”和“train-other-500”的组合),并在带有相应转录文本的相同音频上针对 ASR 进行微调。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_LARGE_LV60K_10M¶
WAV2VEC2_ASR_LARGE_LV60K_100H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_LARGE_LV60K_100H¶ 使用额外的线性模块构建“large-lv60k”wav2vec2 模型
在来自Libri-Light数据集 [3] 的 60,000 小时无标签音频上进行预训练,并在来自LibriSpeech数据集 [1](“train-clean-100”子集)的 100 小时转录音频上针对 ASR 进行微调。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
WAV2VEC2_ASR_LARGE_LV60K_960H¶
-
torchaudio.pipelines.WAV2VEC2_ASR_LARGE_LV60K_960H¶ 使用额外的线性模块构建“large-lv60k”wav2vec2 模型
在来自 Libri-Light [3] 数据集的 60,000 小时无标签音频上进行预训练,并在来自 LibriSpeech 数据集 [1] 的 960 小时转录音频上针对 ASR 进行微调(“train-clean-100”、“train-clean-360”和“train-other-500”的组合)。
最初由 wav2vec 2.0 [2] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
HUBERT_ASR_LARGE¶
-
torchaudio.pipelines.HUBERT_ASR_LARGE¶ 采用“大型”配置的 HuBERT 模型。
在来自Libri-Light数据集的 60,000 小时未标注音频上进行预训练 [3],并在来自LibriSpeech数据集的 960 小时已转录音频上针对 ASR 进行了微调 [1] (包括“train-clean-100”、“train-clean-360”和“train-other-500”的组合)。
最初由 HuBERT [8] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
HUBERT_ASR_XLARGE¶
-
torchaudio.pipelines.HUBERT_ASR_XLARGE¶ 采用“超大”配置的 HuBERT 模型。
在来自Libri-Light数据集的 60,000 小时未标注音频上进行预训练 [3],并在来自LibriSpeech数据集的 960 小时已转录音频上针对 ASR 进行了微调 [1] (包括“train-clean-100”、“train-clean-360”和“train-other-500”的组合)。
最初由 HuBERT [8] 的作者发布,采用 MIT 许可证,并以相同许可证重新分发。 [许可证, 源码]
有关用法,请参阅
torchaudio.pipelines.Wav2Vec2ASRBundle()。
Tacotron2 文本转语音¶
Tacotron2TTSBundle¶
-
class
torchaudio.pipelines.Tacotron2TTSBundle[source]¶ 用于捆绑关联信息以使用预训练 Tacotron2 和声码器的数据类。
此类提供用于实例化预训练模型的接口,以及检索预训练权重和与该模型配合使用的附加数据所需的信息。
Torchaudio 库会实例化此类对象,每个对象代表一个不同的预训练模型。客户端代码应通过这些实例访问预训练模型。
请参阅下方了解用法和可用值。
- Example - Character-based TTS pipeline with Tacotron2 and WaveRNN
>>> import torchaudio >>> >>> text = "Hello, T T S !" >>> bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_CHAR_LJSPEECH >>> >>> # Build processor, Tacotron2 and WaveRNN model >>> processor = bundle.get_text_processor() >>> tacotron2 = bundle.get_tacotron2() Downloading: 100%|███████████████████████████████| 107M/107M [00:01<00:00, 87.9MB/s] >>> vocoder = bundle.get_vocoder() Downloading: 100%|███████████████████████████████| 16.7M/16.7M [00:00<00:00, 78.1MB/s] >>> >>> # Encode text >>> input, lengths = processor(text) >>> >>> # Generate (mel-scale) spectrogram >>> specgram, lengths, _ = tacotron2.infer(input, lengths) >>> >>> # Convert spectrogram to waveform >>> waveforms, lengths = vocoder(specgram, lengths) >>> >>> torchaudio.save('hello-tts.wav', waveforms[0], vocoder.sample_rate)
- Example - Phoneme-based TTS pipeline with Tacotron2 and WaveRNN
>>> >>> # Note: >>> # This bundle uses pre-trained DeepPhonemizer as >>> # the text pre-processor. >>> # Please install deep-phonemizer. >>> # See https://github.com/as-ideas/DeepPhonemizer >>> # The pretrained weight is automatically downloaded. >>> >>> import torchaudio >>> >>> text = "Hello, TTS!" >>> bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONEME_LJSPEECH >>> >>> # Build processor, Tacotron2 and WaveRNN model >>> processor = bundle.get_text_processor() Downloading: 100%|███████████████████████████████| 63.6M/63.6M [00:04<00:00, 15.3MB/s] >>> tacotron2 = bundle.get_tacotron2() Downloading: 100%|███████████████████████████████| 107M/107M [00:01<00:00, 87.9MB/s] >>> vocoder = bundle.get_vocoder() Downloading: 100%|███████████████████████████████| 16.7M/16.7M [00:00<00:00, 78.1MB/s] >>> >>> # Encode text >>> input, lengths = processor(text) >>> >>> # Generate (mel-scale) spectrogram >>> specgram, lengths, _ = tacotron2.infer(input, lengths) >>> >>> # Convert spectrogram to waveform >>> waveforms, lengths = vocoder(specgram, lengths) >>> >>> torchaudio.save('hello-tts.wav', waveforms[0], vocoder.sample_rate)
-
abstract
get_text_processor(self, *, dl_kwargs=None) → torchaudio.pipelines.Tacotron2TTSBundle.TextProcessor[source]¶ 创建文本处理器
对于基于字符的流水线,该处理器将输入文本按字符拆分。 对于基于音素的流水线,该处理器将输入文本(字素)转换为音素。
如果需要预训练权重文件,
torch.hub.download_url_to_file()将用于下载它。- Parameters
dl_kwargs (关键字参数字典,) – 传递给
torch.hub.download_url_to_file()。- Returns
一个可调用对象,它接受字符串或字符串列表作为输入,并返回编码文本的张量(Tensor)和有效长度的张量。 该对象还具有
tokens属性,可用于还原分词形式。- Return type
TTSTextProcessor
- Example - Character-based
>>> text = [ >>> "Hello World!", >>> "Text-to-speech!", >>> ] >>> bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_CHAR_LJSPEECH >>> processor = bundle.get_text_processor() >>> input, lengths = processor(text) >>> >>> print(input) tensor([[19, 16, 23, 23, 26, 11, 34, 26, 29, 23, 15, 2, 0, 0, 0], [31, 16, 35, 31, 1, 31, 26, 1, 30, 27, 16, 16, 14, 19, 2]], dtype=torch.int32) >>> >>> print(lengths) tensor([12, 15], dtype=torch.int32) >>> >>> print([processor.tokens[i] for i in input[0, :lengths[0]]]) ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!'] >>> print([processor.tokens[i] for i in input[1, :lengths[1]]]) ['t', 'e', 'x', 't', '-', 't', 'o', '-', 's', 'p', 'e', 'e', 'c', 'h', '!']
- Example - Phoneme-based
>>> text = [ >>> "Hello, T T S !", >>> "Text-to-speech!", >>> ] >>> bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH >>> processor = bundle.get_text_processor() Downloading: 100%|███████████████████████████████| 63.6M/63.6M [00:04<00:00, 15.3MB/s] >>> input, lengths = processor(text) >>> >>> print(input) tensor([[54, 20, 65, 69, 11, 92, 44, 65, 38, 2, 0, 0, 0, 0], [81, 40, 64, 79, 81, 1, 81, 20, 1, 79, 77, 59, 37, 2]], dtype=torch.int32) >>> >>> print(lengths) tensor([10, 14], dtype=torch.int32) >>> >>> print([processor.tokens[i] for i in input[0]]) ['HH', 'AH', 'L', 'OW', ' ', 'W', 'ER', 'L', 'D', '!', '_', '_', '_', '_'] >>> print([processor.tokens[i] for i in input[1]]) ['T', 'EH', 'K', 'S', 'T', '-', 'T', 'AH', '-', 'S', 'P', 'IY', 'CH', '!']
-
abstract
get_tacotron2(self, *, dl_kwargs=None) → torchaudio.models.Tacotron2[source]¶ 创建带有预训练权重的 Tacotron2 模型。
- Parameters
dl_kwargs (关键字参数字典) – 传递给
torch.hub.load_state_dict_from_url()。- Returns
生成的模型。
- Return type
-
abstract
get_vocoder(self, *, dl_kwargs=None) → torchaudio.pipelines.Tacotron2TTSBundle.Vocoder[source]¶ 创建一个基于 WaveRNN 或 GriffinLim 的声码器模块。
如果需要预训练权重文件,
torch.hub.load_state_dict_from_url()将用于下载它。- Parameters
dl_kwargs (关键字参数字典) – 传递给
torch.hub.load_state_dict_from_url()。- Returns
一个声码器模块,它接收频谱张量和一个可选的长度张量,然后返回生成的波形张量和一个可选的长度张量。
- Return type
Callable[[Tensor, Optional[Tensor]], Tuple[Tensor, Optional[Tensor]]]
使用 Tacotron2TTSBundle¶ 的示例
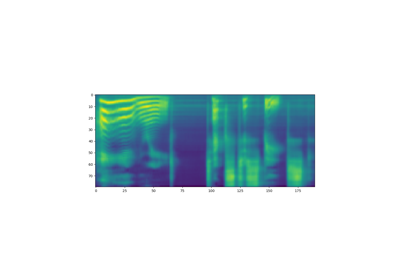
Tacotron2TTSBundle - 文本处理器¶
-
class
Tacotron2TTSBundle.TextProcessor[source]¶ Tacotron2TTS 流程中文本处理部分的接口
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_text_processor()了解用法。-
abstract
__call__(texts: Union[str, List[str]]) → Tuple[torch.Tensor, torch.Tensor]¶ 将给定的(一批)文本编码为数值张量
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_text_processor()了解用法。- Parameters
text (str 或 str 列表) – 输入文本。
- Returns
- Tensor:
编码后的文本。形状:(batch, max length)
- Tensor:
批次中每个样本的有效长度。形状:(batch, )。
- Return type
(张量,张量)
-
abstract property
tokens¶ 处理后的张量中每个值所代表的标记。
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_text_processor()了解用法。- Type
列表[字符串]
-
abstract
Tacotron2TTSBundle - 声码器¶
-
class
Tacotron2TTSBundle.Vocoder[source]¶ Tacotron2TTS 流程中声码器部分的接口
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_vocoder()了解用法。-
abstract
__call__(specgrams: torch.Tensor, lengths: Optional[torch.Tensor] = None) → Tuple[torch.Tensor, Optional[torch.Tensor]]¶ 根据给定的输入(例如频谱图)生成波形。
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_vocoder()了解用法。- Parameters
specgrams (Tensor) – 输入频谱图。形状:(batch, frequency bins, time)。 预期形状取决于具体实现。
lengths (Tensor 或 None,可选) – 批次中每个样本的有效长度。形状:(batch, )。 (默认值:None)
- Returns
- Tensor:
生成的波形。形状:(batch, max length)
- Tensor or None:
批次中每个样本的有效长度。形状:(batch, )。
- Return type
(张量,可选[张量])
-
abstract property
sample_rate¶ 生成波形的采样率
查看
torchaudio.pipelines.Tacotron2TTSBundle.get_vocoder()了解用法。- Type
-
abstract
TACOTRON2_WAVERNN_PHONE_LJSPEECH¶
-
torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH¶ 基于音素的TTS流程,包含
torchaudio.models.Tacotron2和torchaudio.models.WaveRNN。文本处理器基于音素对输入文本进行编码。 它使用 DeepPhonemizer 将字母转换为音素。 该模型(en_us_cmudict_forward)是在 CMUDict 上训练的。
Tacotron2 在 LJSpeech [9] 数据集上训练了 1,500 个 epoch。 您可以在 此处 找到训练脚本。 使用了以下参数;
win_length=1100、hop_length=275、n_fft=2048、mel_fmin=40和mel_fmax=11025。该 vocder 基于
torchaudio.models.WaveRNN。 它在 LJSpeech [9] 的 8 位深度波形上进行了训练,共 10,000 个 epoch。 您可以在 此处 找到训练脚本。有关用法,请参阅
torchaudio.pipelines.Tacotron2TTSBundle()。示例 - “你好,世界!T T S 代表文本转语音!”

示例——“专家们的审查和证词使委员会得出结论,可能开火了五枪。”

TACOTRON2_WAVERNN_CHAR_LJSPEECH¶
-
torchaudio.pipelines.TACOTRON2_WAVERNN_CHAR_LJSPEECH¶ 基于字符的TTS流程,包含
torchaudio.models.Tacotron2和torchaudio.models.WaveRNN。文本处理器逐字符地对输入文本进行编码。
Tacotron2 在 LJSpeech [9] 数据集上训练了 1,500 个 epoch。 您可以在 此处 找到训练脚本。 使用了以下参数;
win_length=1100、hop_length=275、n_fft=2048、mel_fmin=40和mel_fmax=11025。该 vocder 基于
torchaudio.models.WaveRNN。 它在 LJSpeech [9] 的 8 位深度波形上进行了训练,共 10,000 个 epoch。 您可以在 此处 找到训练脚本。有关用法,请参阅
torchaudio.pipelines.Tacotron2TTSBundle()。示例 - “你好,世界!T T S 代表文本转语音!”

示例——“专家们的审查和证词使委员会得出结论,可能开火了五枪。”

TACOTRON2_GRIFFINLIM_PHONE_LJSPEECH¶
-
torchaudio.pipelines.TACOTRON2_GRIFFINLIM_PHONE_LJSPEECH¶ 基于音素的TTS流程,包含
torchaudio.models.Tacotron2和torchaudio.transforms.GriffinLim。文本处理器基于音素对输入文本进行编码。 它使用 DeepPhonemizer 将字母转换为音素。 该模型(en_us_cmudict_forward)是在 CMUDict 上训练的。
Tacotron2 在 LJSpeech [9] 数据集上训练了 1,500 个 epoch。 您可以在 此处 找到训练脚本。 文本处理器已设置为 “english_phonemes”。
该声码器基于
torchaudio.transforms.GriffinLim。有关用法,请参阅
torchaudio.pipelines.Tacotron2TTSBundle()。示例 - “你好,世界!T T S 代表文本转语音!”

示例——“专家们的审查和证词使委员会得出结论,可能开火了五枪。”

TACOTRON2_GRIFFINLIM_CHAR_LJSPEECH¶
-
torchaudio.pipelines.TACOTRON2_GRIFFINLIM_CHAR_LJSPEECH¶ 基于字符的TTS流程,包含
torchaudio.models.Tacotron2和torchaudio.transforms.GriffinLim。文本处理器逐字符地对输入文本进行编码。
Tacotron2 在 LJSpeech [9] 数据集上训练了 1,500 个 epoch。 您可以在 此处 找到训练脚本。 使用了默认参数。
该声码器基于
torchaudio.transforms.GriffinLim。有关用法,请参阅
torchaudio.pipelines.Tacotron2TTSBundle()。示例 - “你好,世界!T T S 代表文本转语音!”

示例——“专家们的审查和证词使委员会得出结论,可能开火了五枪。”

参考文献¶
- 1(1,2,3,4,5,6,7,8,9,10,11,12,13)
Vassil Panayotov, Guoguo Chen, Daniel Povey, 和 Sanjeev Khudanpur。Librispeech:一个基于公共领域有声书的语音识别语料库。在 2015 IEEE 国际声学、语音与信号处理会议(ICASSP),卷,5206–5210。2015。 doi:10.1109/ICASSP.2015.7178964.
- 2(1,2,3,4,5,6,7,8,9,10,11,12)
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, 和 Michael Auli. Wav2vec 2.0: 一个用于语音表示自监督学习的框架。2020. arXiv:2006.11477.
- 3(1,2,3,4,5,6,7,8,9,10)
J. Kahn, M. Rivière, W. Zheng, E. Kharitonov, Q. Xu, P. E. Mazaré, J. Karadayi, V. Liptchinsky, R. Collobert, C. Fuegen, T. Likhomanenko, G. Synnaeve, A. Joulin, A. Mohamed, and E. Dupoux. Libri-light: 一个用于有限或无监督的语音识别的基准。In ICASSP 2020 - 2020 IEEE 国际声学、语音和信号处理会议(ICASSP), 7669–7673. 2020. https://github.com/facebookresearch/libri-light.
- 4
Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, 和 Ronan Collobert。Mls:一个用于语音研究的大规模多语言数据集。Interspeech 2020,2020年10月。URL:http://dx.doi.org/10.21437/Interspeech.2020-2826,doi:10.21437/interspeech.2020-2826。
- 5
Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, 和 Gregor Weber。Common voice: 一个大规模多语言语音语料库。2020。 arXiv:1912.06670.
- 6
Mark John Francis Gales, Kate Knill, Anton Ragni, 和 Shakti Prasad Rath。面向低资源语言的语音识别与关键词检测:CUEd 的 Babel 项目研究。发表于 SLTU。2014 年。
- 7
Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, 和 Michael Auli. 用于语音识别的无监督跨语言表征学习. 2020. arXiv:2006.13979.
- 8(1,2,3,4,5)
魏宁 胡, 本杰明·博尔特, 姚宏·赫伯特·蔡, 库沙尔·拉克霍蒂亚, 鲁斯兰·萨拉胡丁诺夫, 和阿卜杜勒拉赫曼·穆罕默德。Hubert:通过隐藏单元的掩码预测进行自监督语音表征学习。2021。arXiv:2106.07447.
- 9(1,2,3,4,5,6)
Keith Ito 和 Linda Johnson。The lj speech dataset。https://keithito.com/LJ-Speech-Dataset/,2017。