使用NVIDIA MPS运行TorchServe ¶
为了部署ML模型,TorchServe会在每个worker上启动一个单独的进程,从而将每个worker与其他worker隔离。每个进程都会创建自己的CUDA上下文来执行其内核并访问分配的内存。
虽然NVIDIA显卡在默认设置下允许多个进程在同一设备上运行CUDA内核,但这涉及以下缺点:
核函数的执行通常串行化
每个进程都会创建自己的CUDA上下文,占用额外的GPU内存。
对于这些场景,NVIDIA 提供了多进程服务(MPS),它:
允许多个进程在同一GPU上共享相同的CUDA上下文
在并行模式下运行他们的核。
这可能导致:
在同一个GPU上使用多个工作线程时,性能有所提升。
减少GPU内存使用率,由于共享上下文
为了利用NVIDIA MPS的益处,我们需要在启动TorchServe之前使用以下命令启动MPS守护进程。
sudo nvidia-smi -c 3
nvidia-cuda-mps-control -d
第一个命令启用GPU的独占处理模式,仅允许一个进程(MPS守护进程)使用它。 第二个命令启动MPS守护进程本身。 要关闭守护进程,我们可以执行:
echo quit | nvidia-cuda-mps-control
有关MPS的更多详情,请参阅NVIDIA的MPS文档。 需要注意的是,由于硬件资源有限,MPS仅允许48个进程(对于Volta GPU)连接到守护程序。 向同一GPU添加更多客户端/工作者将导致失败。
性能指标¶
为了展示TorchServe在激活MPS后的性能,并帮助您决定是否启用MPS以部署您的应用程序,我们将使用代表性的工作负载进行一些基准测试。
首先,我们想研究在激活MPS的情况下,不同操作点的工作者吞吐量如何演变。 作为我们基准测试的工作负载示例,我们选择了 HuggingFace Transformers 序列分类示例。 我们在AWS的g4dn.4xlarge和p3.2xlarge实例上进行基准测试。 这两种实例类型每台实例提供一个GPU,这将导致多个工作者在同一GPU上调度。 对于基准测试,我们重点关注由 benchmark-ab.py 工具测量的模型吞吐量。
首先,我们测量单个工作者在不同批次大小下的吞吐量,因为这将告诉我们GPU的计算资源何时完全被占用。 其次,我们测量两个部署的工作者在我们预计GPU仍有剩余资源可以共享的批次大小下的吞吐量。 对于每个基准测试,我们进行五次运行,并取这些运行的中位数。
我们使用以下config.json作为基准配置,仅相应地覆盖了工作线程数和批量大小。
{
"url":"/home/ubuntu/serve/examples/Huggingface_Transformers/model_store/BERTSeqClassification",
"requests": 10000,
"concurrency": 600,
"input": "/home/ubuntu/serve/examples/Huggingface_Transformers/Seq_classification_artifacts/sample_text_captum_input.txt",
"workers": "1"
}
请注意,我们设置了并发级别为600,这将确保TorchServe内部的批量聚合达到最大批次大小。但同时,这也会使延迟测量失衡,因为许多请求将在队列中等待处理。因此,我们将忽略以下延迟测量。
G4实例¶
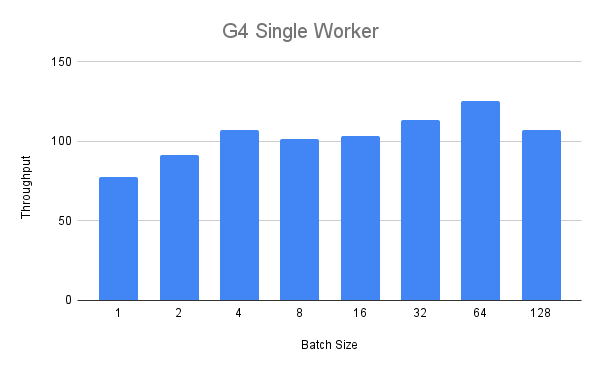
我们首先对G4实例进行单个工作者基准测试。 在下面的图中,我们可以看到,在批量大小为四个时,通过量随批量大小的增加而稳步增长。
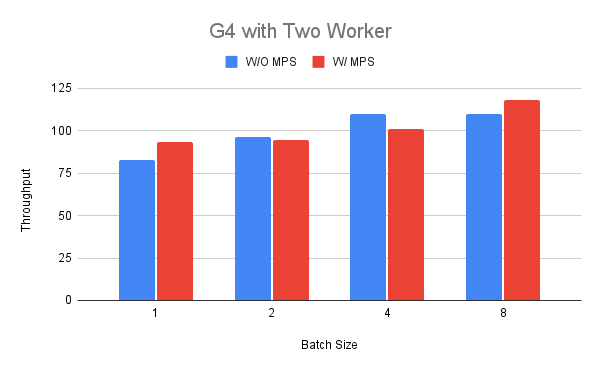
接下来,我们增加工作者的数量到两个,以便比较MPS运行时和不运行时的吞吐量。 为了启用MPS对于第二组运行,我们首先将GPU设置为独占处理模式,然后启动如上图所示的MPS守护进程。
我们根据以往的研究结果选择批处理大小在1到8之间。 在图中我们可以看到,对于批处理大小为1和8的情况(最多可提高18%),性能在吞吐量方面可以更好;而对于其他情况,则可能会更差(降低11%)。 这种结果的解释可能是,当我们运行BERT模型时,G4实例没有多少资源可供共享。
P3实例¶
接下来,我们将使用更大的p3.2xlarge实例运行相同的实验。单个工作者的以下吞吐量值如下:
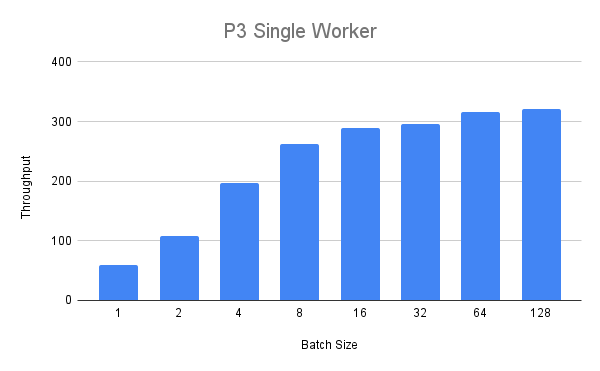
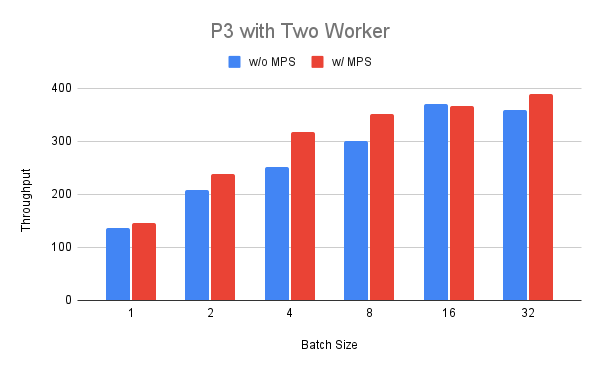
我们可以看到吞吐量稳步增加,但当批次大小超过八时,我们看到了回报递减的现象。 最后,我们在P3实例上部署了两个工作进程,并比较了它们在启用MPS和不启用MPS时的运行情况。 我们可以看到,在1到32的批次大小之间,启用MPS时的吞吐量始终更高(最高可达+25%),除了批次大小为16的情况。
摘要¶
在前一节中,我们看到通过为两个运行相同模型的工作者启用 MPS,我们可以获得混合结果。 对于较小的 G4 实例,我们只看到了某些操作点的好处,而我们在较大的 P3 实例上看到了更一致的改进。 这表明,在使用 MPS 运行部署时,性能增益高度依赖于工作负载和环境,并需要根据特定情况使用适当的基准测试工具进行确定。 需要注意的是,之前的基准测试仅专注于吞吐量,忽略了延迟和内存占用。 由于使用 MPS 只会创建一个 CUDA上下文,因此可以将更多的工作者打包到同一 GPU 上,这也需要在相应的场景中加以考虑。