注意
点击 这里 下载完整示例代码
振荡器和 ADSR 包络¶
作者: Moto Hira
本教程展示了如何使用
oscillator_bank() 和
adsr_envelope() 合成各种波形。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.6.0.dev20241104
2.5.0.dev20241105
try:
from torchaudio.prototype.functional import adsr_envelope, oscillator_bank
except ModuleNotFoundError:
print(
"Failed to import prototype DSP features. "
"Please install torchaudio nightly builds. "
"Please refer to https://pytorch.org/get-started/locally "
"for instructions to install a nightly build."
)
raise
import math
import matplotlib.pyplot as plt
from IPython.display import Audio
PI = torch.pi
PI2 = 2 * torch.pi
振荡器组¶
正弦振荡器根据给定的幅度和频率生成正弦波形。
其中相位 \(\theta_t\) 是通过对瞬时频率 \(f_t\) 进行积分得到的。
注意
为什么要整合频率?瞬时频率表示在给定时间点的振荡速度。因此,对瞬时频率进行积分可以得到自开始以来振荡相位的位移。
在离散时间信号处理中,积分变为累加。
在PyTorch中,可以使用 torch.cumsum() 来计算累加。
torchaudio.prototype.functional.oscillator_bank() 从幅度包络和瞬时频率生成一组正弦波形。
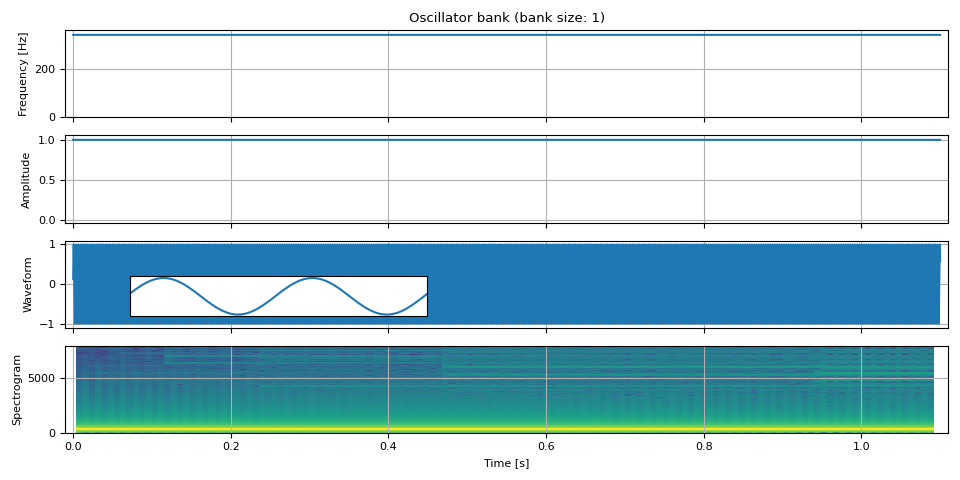
简单正弦波¶
让我们从一个简单的例子开始。
首先,我们生成一个在所有地方频率和振幅都保持恒定的正弦波,即一个普通的正弦波。
我们定义一些常量和辅助函数,这些将在教程的其余部分中使用。
F0 = 344.0 # fundamental frequency
DURATION = 1.1 # [seconds]
SAMPLE_RATE = 16_000 # [Hz]
NUM_FRAMES = int(DURATION * SAMPLE_RATE)
def show(freq, amp, waveform, sample_rate, zoom=None, vol=0.3):
t = (torch.arange(waveform.size(0)) / sample_rate).numpy()
fig, axes = plt.subplots(4, 1, sharex=True)
axes[0].plot(t, freq.numpy())
axes[0].set(title=f"Oscillator bank (bank size: {amp.size(-1)})", ylabel="Frequency [Hz]", ylim=[-0.03, None])
axes[1].plot(t, amp.numpy())
axes[1].set(ylabel="Amplitude", ylim=[-0.03 if torch.all(amp >= 0.0) else None, None])
axes[2].plot(t, waveform.numpy())
axes[2].set(ylabel="Waveform")
axes[3].specgram(waveform, Fs=sample_rate)
axes[3].set(ylabel="Spectrogram", xlabel="Time [s]", xlim=[-0.01, t[-1] + 0.01])
for i in range(4):
axes[i].grid(True)
pos = axes[2].get_position()
plt.tight_layout()
if zoom is not None:
ax = fig.add_axes([pos.x0 + 0.01, pos.y0 + 0.03, pos.width / 2.5, pos.height / 2.0])
ax.plot(t, waveform)
ax.set(xlim=zoom, xticks=[], yticks=[])
waveform /= waveform.abs().max()
return Audio(vol * waveform, rate=sample_rate, normalize=False)
现在我们用恒定的频率和振幅合成音频
freq = torch.full((NUM_FRAMES, 1), F0)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
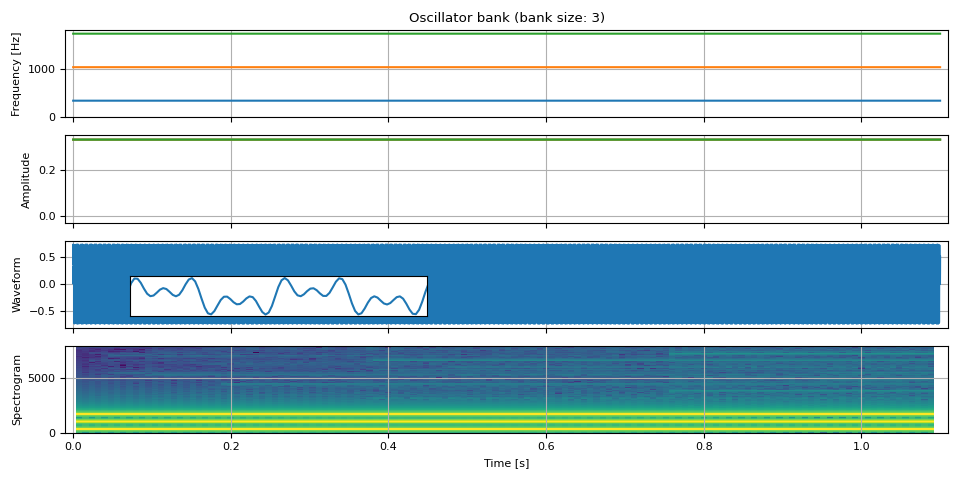
组合多个正弦波¶
oscillator_bank() 可以
结合任意数量的正弦波来生成波形。
freq = torch.empty((NUM_FRAMES, 3))
freq[:, 0] = F0
freq[:, 1] = 3 * F0
freq[:, 2] = 5 * F0
amp = torch.ones((NUM_FRAMES, 3)) / 3
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
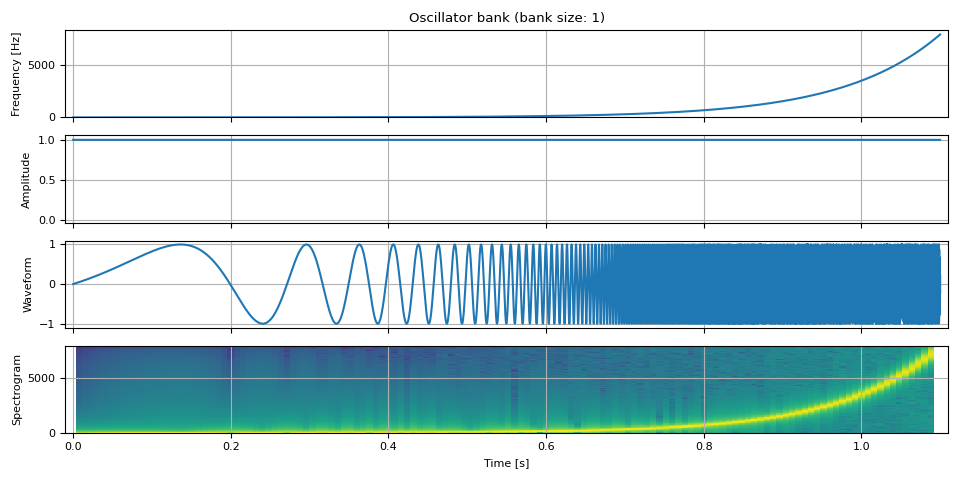
随时间变化的频率¶
让我们随着时间改变频率。在这里,我们将频率从零变化到奈奎斯特频率(采样率的一半),以对数尺度进行,这样更容易观察波形的变化。
nyquist_freq = SAMPLE_RATE / 2
freq = torch.logspace(0, math.log(0.99 * nyquist_freq, 10), NUM_FRAMES).unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, vol=0.2)
我们也可以调整振荡频率。
fm = 2.5 # rate at which the frequency oscillates
f_dev = 0.9 * F0 # the degree of frequency oscillation
freq = F0 + f_dev * torch.sin(torch.linspace(0, fm * PI2 * DURATION, NUM_FRAMES))
freq = freq.unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)

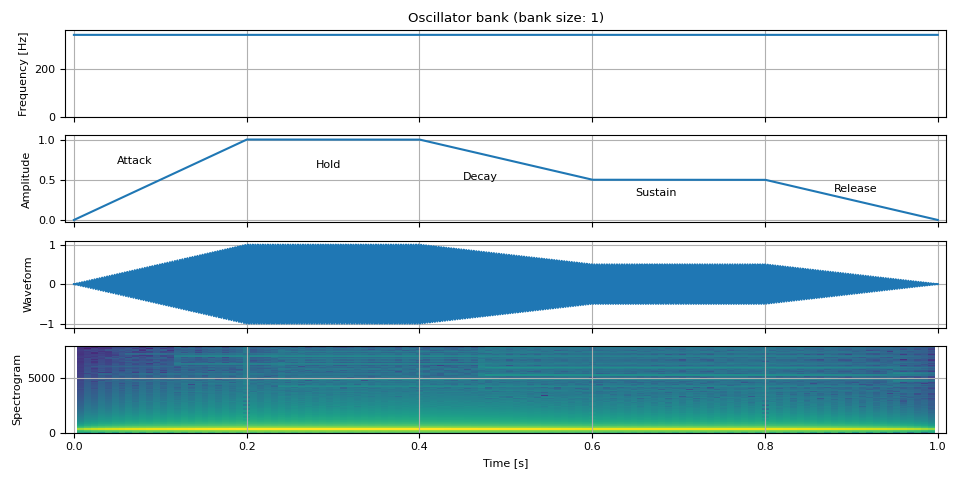
ADSR包络¶
接下来,我们改变随时间变化的幅度。一种常用的建模幅度的技术是 ADSR 包络。
ADSR 代表 Attack(攻击)、Decay(衰减)、Sustain(保持)和 Release(释放)。
Attack is the time it takes to reach from zero to the top level.
Decay is the time it takes from the top to reach sustain level.
Sustain is the level at which the level stays constant.
Release is the time it takes to drop to zero from sustain level.
ADSR 模型有许多变体,此外,一些模型具有以下特性
Hold: The time the level stays at the top level after attack.
non-linear decay/release: The decay and release take non-linear change.
adsr_envelope 支持
hold 和多项式衰减。
freq = torch.full((SAMPLE_RATE, 1), F0)
amp = adsr_envelope(
SAMPLE_RATE,
attack=0.2,
hold=0.2,
decay=0.2,
sustain=0.5,
release=0.2,
n_decay=1,
)
amp = amp.unsqueeze(-1)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
audio = show(freq, amp, waveform, SAMPLE_RATE)
ax = plt.gcf().axes[1]
ax.annotate("Attack", xy=(0.05, 0.7))
ax.annotate("Hold", xy=(0.28, 0.65))
ax.annotate("Decay", xy=(0.45, 0.5))
ax.annotate("Sustain", xy=(0.65, 0.3))
ax.annotate("Release", xy=(0.88, 0.35))
audio
现在让我们来看一些如何使用 ADSR 包络来创建不同声音的例子。
以下示例灵感来源于 这篇文章。
鼓点¶
unit = NUM_FRAMES // 3
repeat = 9
freq = torch.empty((unit * repeat, 2))
freq[:, 0] = F0 / 9
freq[:, 1] = F0 / 5
amp = torch.stack(
(
adsr_envelope(unit, attack=0.01, hold=0.125, decay=0.12, sustain=0.05, release=0),
adsr_envelope(unit, attack=0.01, hold=0.25, decay=0.08, sustain=0, release=0),
),
dim=-1,
)
amp = amp.repeat(repeat, 1) / 2
bass = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, bass, SAMPLE_RATE, vol=0.5)
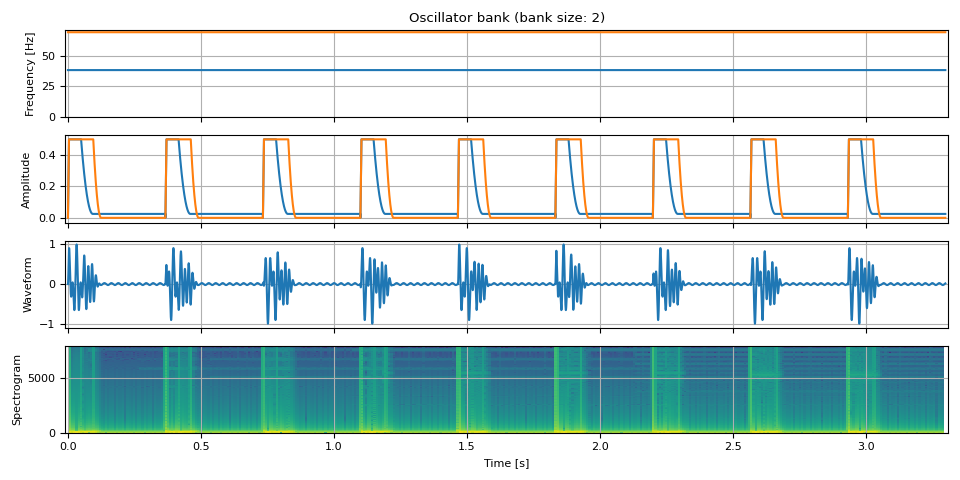
摘取¶
tones = [
513.74, # do
576.65, # re
647.27, # mi
685.76, # fa
769.74, # so
685.76, # fa
647.27, # mi
576.65, # re
513.74, # do
]
freq = torch.cat([torch.full((unit, 1), tone) for tone in tones], dim=0)
amp = adsr_envelope(unit, attack=0, decay=0.7, sustain=0.28, release=0.29)
amp = amp.repeat(9).unsqueeze(-1)
doremi = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, doremi, SAMPLE_RATE)
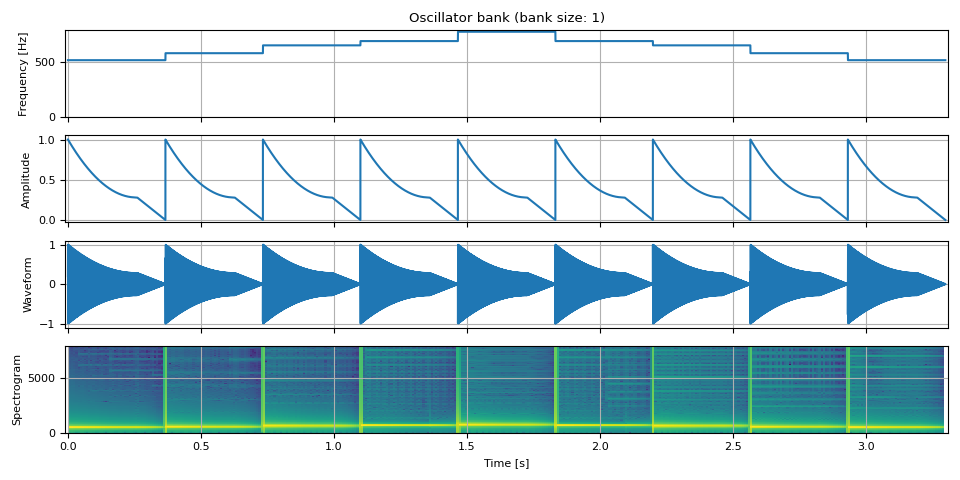
Riser¶
env = adsr_envelope(NUM_FRAMES * 6, attack=0.98, decay=0.0, sustain=1, release=0.02)
tones = [
484.90, # B4
513.74, # C5
576.65, # D5
1221.88, # D#6/Eb6
3661.50, # A#7/Bb7
6157.89, # G8
]
freq = torch.stack([f * env for f in tones], dim=-1)
amp = env.unsqueeze(-1).expand(freq.shape) / len(tones)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)
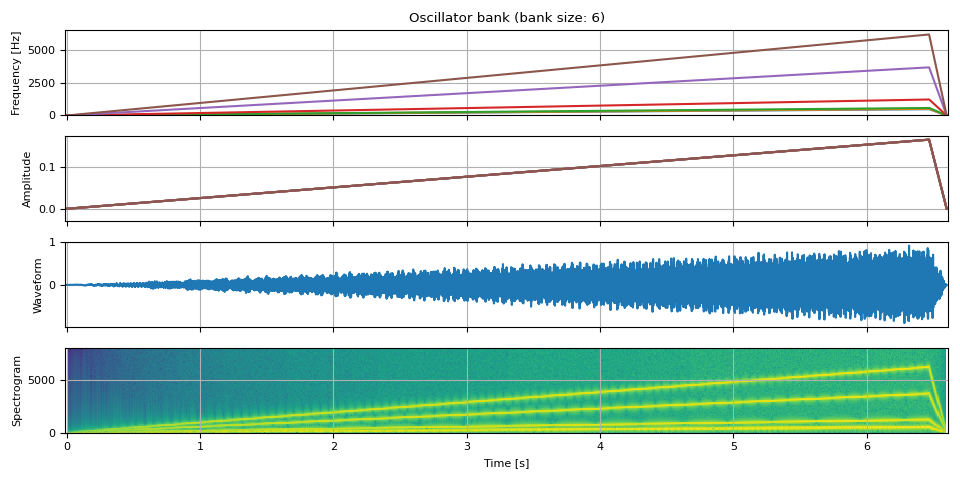
参考文献¶
脚本的总运行时间: ( 0 分钟 3.018 秒)