将Llama3.1 8B通过知识蒸馏提炼为Llama3.2 1B¶
本指南将介绍知识蒸馏(KD),并展示如何使用torchtune将Llama3.1 8B模型蒸馏到Llama3.2 1B模型。 如果您已经了解知识蒸馏,并希望直接在torchtune中运行自己的蒸馏, 您可以跳转到torchtune中的KD教程。
什么是知识蒸馏以及它如何帮助提升模型性能
PyTorch 微调框架 torchtune 中知识蒸馏组件概述
如何使用 torchtune 从教师模型蒸馏到学生模型
如何尝试不同的知识蒸馏配置
熟悉 torchtune
确保已 安装 torchtune
请确保您已下载了 Llama3 模型权重
熟悉 LoRA
什么是知识蒸馏?¶
知识蒸馏 是一种广泛使用的压缩技术,它将知识从较大的(教师)模型转移到较小的(学生)模型。较大的模型具有更多的参数和知识容量,然而,这种更大的容量也更耗费计算资源进行部署。知识蒸馏可以用来将较大模型的知识压缩到较小的模型中。其理念是,通过学习较大模型的输出,可以提升较小模型的性能。
知识蒸馏是如何工作的?¶
知识通过在一个迁移集上训练学生模型,使其模仿教师模型的词元级概率分布,从而从教师模型传递给学生模型。下图是知识蒸馏工作原理的简化表示。
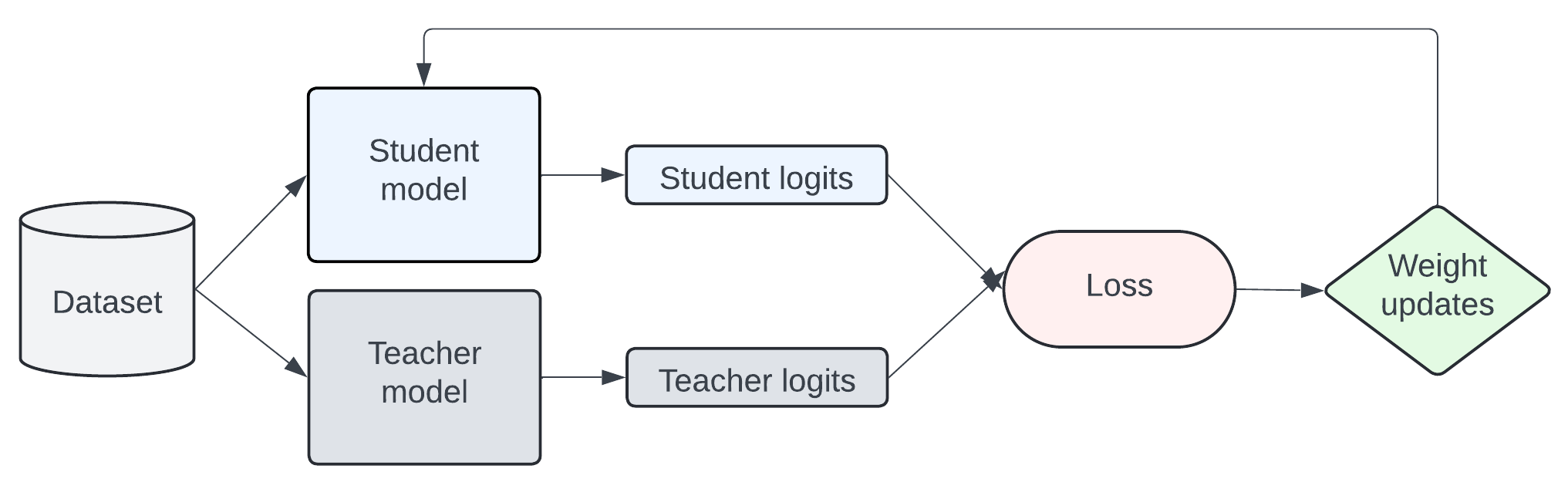
总损失可以通过多种方式进行配置。torchtune中的默认知识蒸馏(KD)配置结合了交叉熵(CE)损失与 前向Kullback-Leibler (KL) 散度损失, 这是标准知识蒸馏方法中使用的方法。前向KL散度的目标是通过使学生模型的分布与教师模型的所有分布对齐来最小化差异。然而,将学生模型的分布与整个教师模型的分布对齐可能并不有效,并且有多篇论文,例如 MiniLLM、 DistiLLM 和 广义知识蒸馏, 提出了新的知识蒸馏损失以解决这些限制。在这个教程中,让我们看看前向KL散度损失的实现。
import torch
import torch.nn.functional as F
class ForwardKLLoss(torch.nn.Module):
def __init__(self, ignore_index: int = -100)
super().__init__()
self.ignore_index = ignore_index
def forward(self, student_logits, teacher_logits, labels) -> torch.Tensor:
# Implementation from https://github.com/jongwooko/distillm
# Computes the softmax of the teacher logits
teacher_prob = F.softmax(teacher_logits, dim=-1, dtype=torch.float32)
# Computes the student log softmax probabilities
student_logprob = F.log_softmax(student_logits, dim=-1, dtype=torch.float32)
# Computes the forward KL divergence
prod_probs = teacher_prob * student_logprob
# Compute the sum
x = torch.sum(prod_probs, dim=-1).view(-1)
# We don't want to include the ignore labels in the average
mask = (labels != self.ignore_index).int()
# Loss is averaged over non-ignored targets
return -torch.sum(x * mask.view(-1), dim=0) / torch.sum(mask.view(-1), dim=0)
省略了一些细节以简化计算,但如果您想了解更多,
可以查看实现 ForwardKLLoss。
默认情况下,KD 配置使用 ForwardKLWithChunkedOutputLoss 来减少内存。
当前实现仅支持学生模型和教师模型具有相同的输出 logits 形状和相同的分词器。
PyTorch中的KD配方¶
使用 torchtune,我们可以轻松地将知识蒸馏应用于 Llama3,以及其他 LLM 模型家族。 让我们看看如何使用 torchtune 的 KD 配方 来蒸馏模型。
首先,请确保您已下载所有模型权重。在本示例中,我们将使用 Llama3.1-8B 作为教师模型,Llama3.2-1B 作为学生模型。
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
接下来,我们将使用 LoRA 对教师模型进行微调。基于我们的实验和以往的研究,我们发现当教师模型已在目标数据集上进行微调时,知识蒸馏(KD)的效果更佳。
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_device
最后,我们可以在单个 GPU 上运行以下命令,将微调后的 8B 模型蒸馏到 1B 模型。
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device
消融研究¶
在之前的示例中,我们使用了LoRA微调的8B教师模型和基线1B学生模型,
但我们可能想尝试不同的配置和超参数。
对于本教程,我们将对 alpaca_cleaned_dataset 进行微调,并通过EleutherAI的 语言模型评估套件 在 truthfulqa_mc2、
hellaswag 和 commonsense_qa 任务上评估模型。
让我们看看以下因素的影响:
使用经过微调的教师模型
使用微调后的学生模型
超参数调优:kd_ratio 与学习率
具有更接近参数数量的教师模型和学生模型
使用微调的教师模型¶
配置中的默认设置使用了微调过的教师模型。现在,让我们先看看不微调教师模型的效果。要更改教师模型,您可以修改配置中的
teacher_checkpointer:
teacher_checkpointer:
_component_: torchtune.training.FullModelHFCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3.1-8B-Instruct/
checkpoint_files: [
model-00001-of-00004.safetensors,
model-00002-of-00004.safetensors,
model-00003-of-00004.safetensors,
model-00004-of-00004.safetensors
]
在下表中,我们可以看到 1B 模型的标准微调比基线 1B 模型取得了更高的准确率。通过使用微调后的 8B 教师模型,我们在 TruthfulQA 上获得了相当的结果,并在 HellaSwag 和常识推理任务上实现了提升。当使用基线 8B 模型作为教师时,我们在所有指标上均观察到改进,但效果低于其他配置。
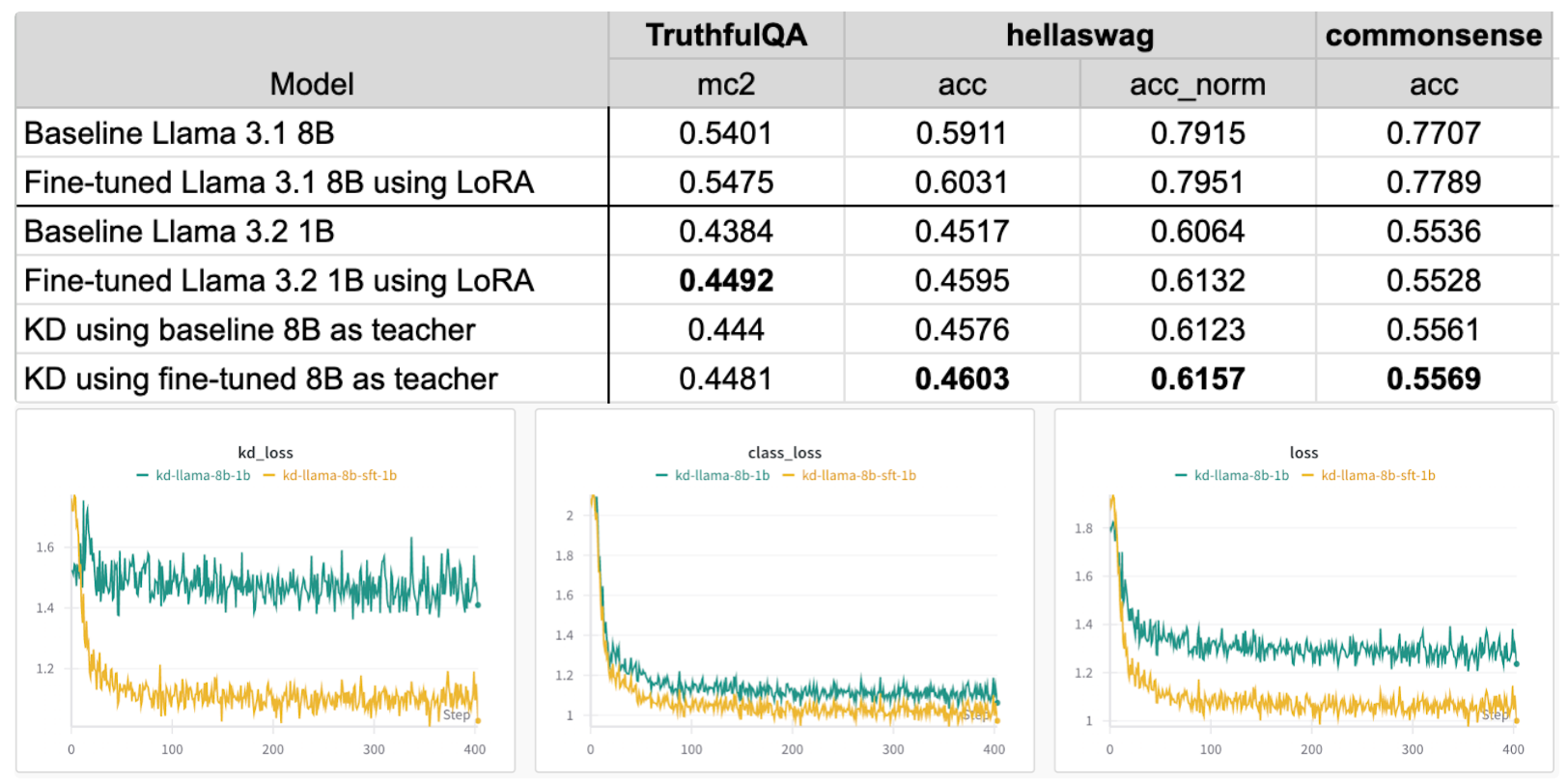
观察损失值,使用基线 8B 模型作为教师模型会导致比使用微调后的教师模型更高的损失。知识蒸馏(KD)损失也保持相对稳定,这表明教师模型的分布应与迁移数据集保持一致。
使用微调的学生模型¶
对于这些实验,让我们看看当学生模型已经经过微调时,知识蒸馏(KD)的效果。在这些实验中,我们考察了不同组合的基线模型和微调后的 8B 与 1B 模型。若要更改学生模型,您可以先对 1B 模型进行微调,然后在配置文件中修改学生模型的检查点保存器:
checkpointer:
_component_: torchtune.training.FullModelHFCheckpointer
checkpoint_dir: /tmp/Llama-3.2-1B-Instruct/
checkpoint_files: [
hf_model_0001_0.pt
]
使用微调后的学生模型可进一步提升 truthfulqa 的准确率,但 hellaswag 和 commonsense 的准确率有所下降。使用微调后的教师模型与基线学生模型在 hellaswag 和 commonsense 数据集上取得了最佳结果。基于这些发现,最佳配置将根据您优化的评估数据集和指标而变化。
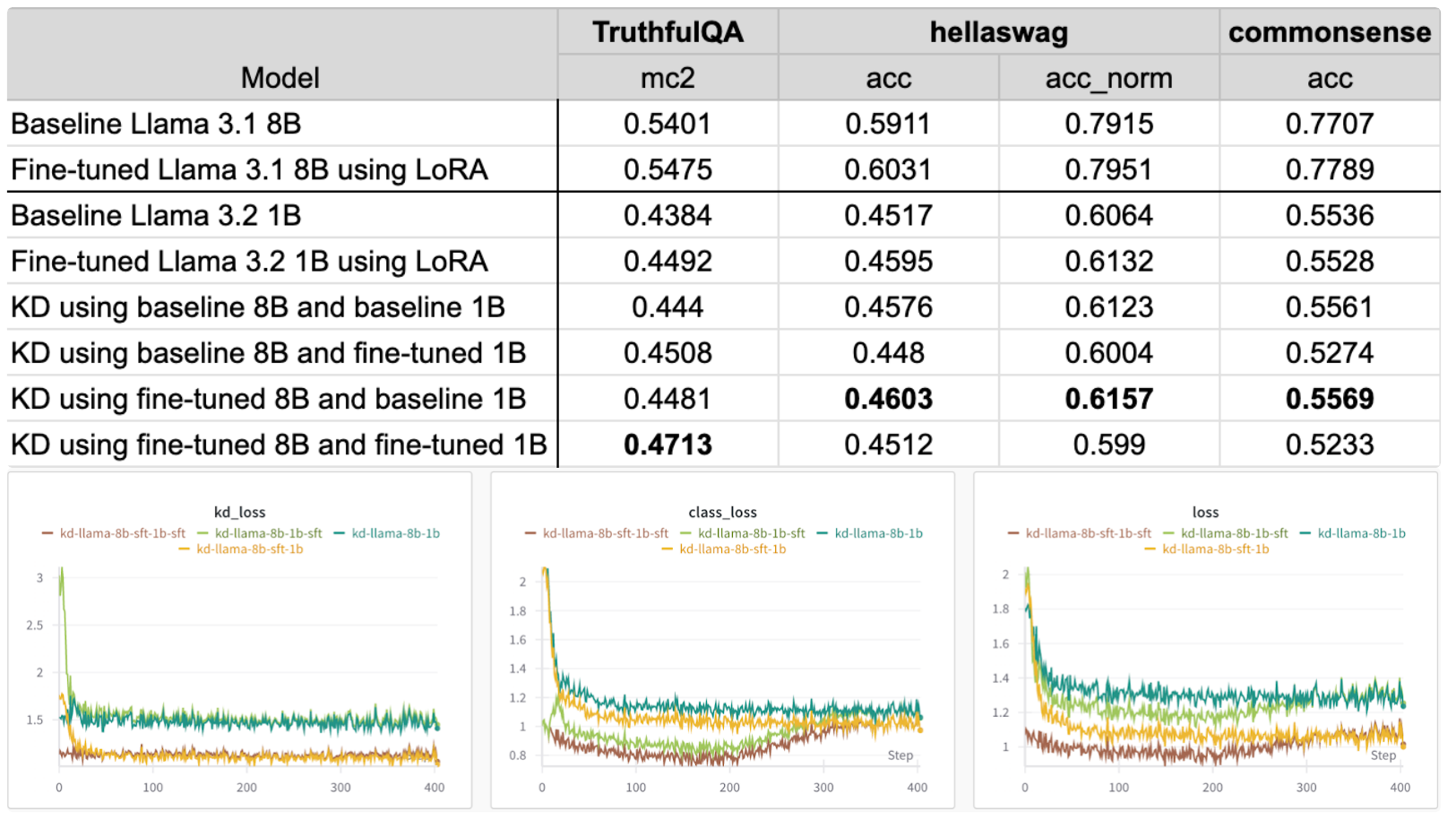
根据损失曲线图,无论学生模型是否进行微调,使用经过微调的教师模型都会带来更低的损失。同样值得注意的是,当使用经过微调的学生模型时,类别损失开始上升。
超参数调优:学习率¶
默认情况下,配置的学习率设置为 \(3e^{-4}\),这与 LoRA 配置相同。在这些实验中, 我们将学习率从最高 \(1e^{-3}\) 调整到最低 \(1e^{-5}\)。要更改学习率, 您可以简单地通过覆盖学习率参数来实现:
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device optimizer.lr=1e-3
根据结果,最佳学习率会根据您优化的指标而变化。
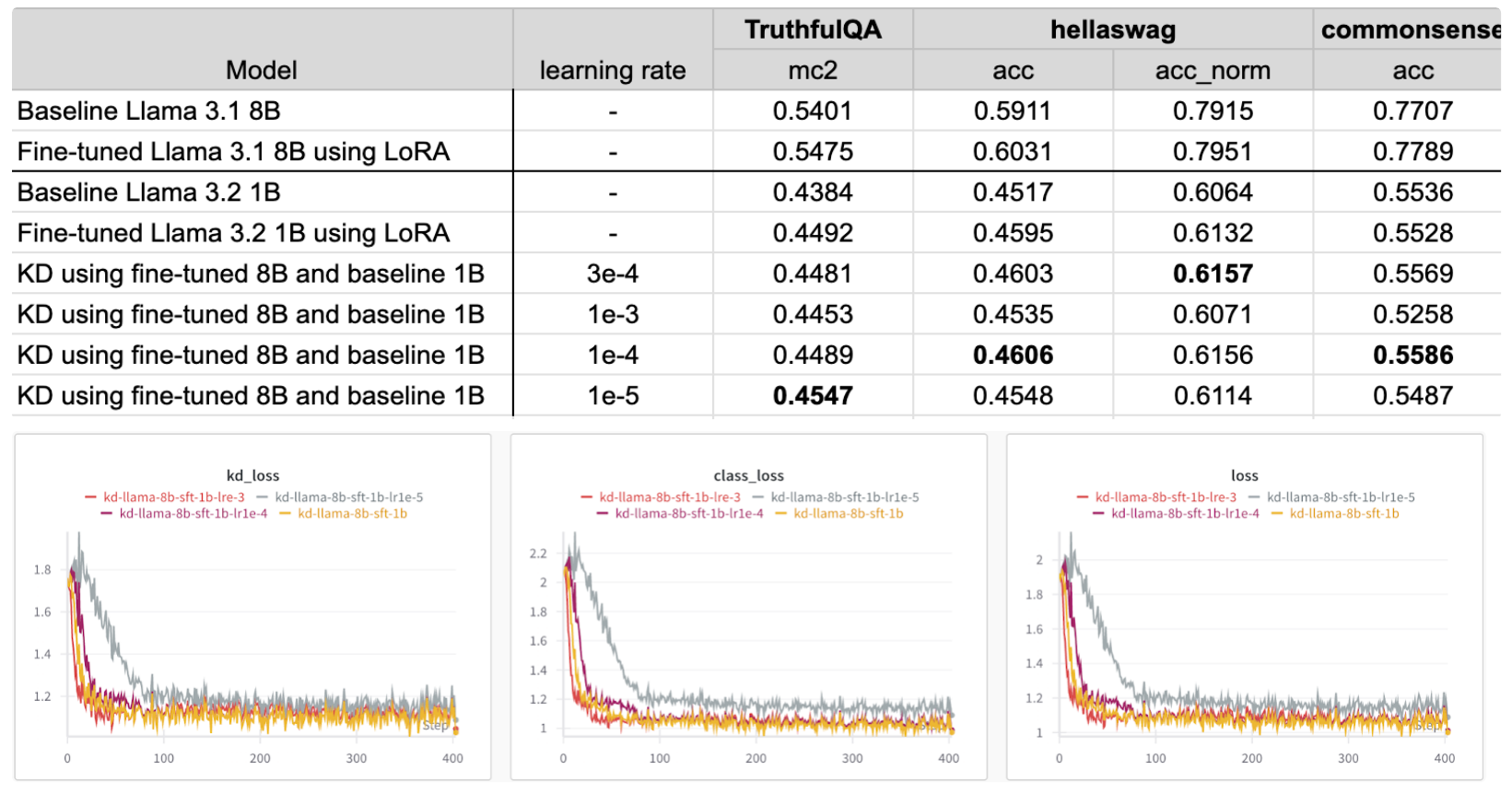
根据损失图,所有学习率的结果损失相似,除了 \(1e^{-5}\),其具有更高的知识蒸馏(KD)和类别损失。
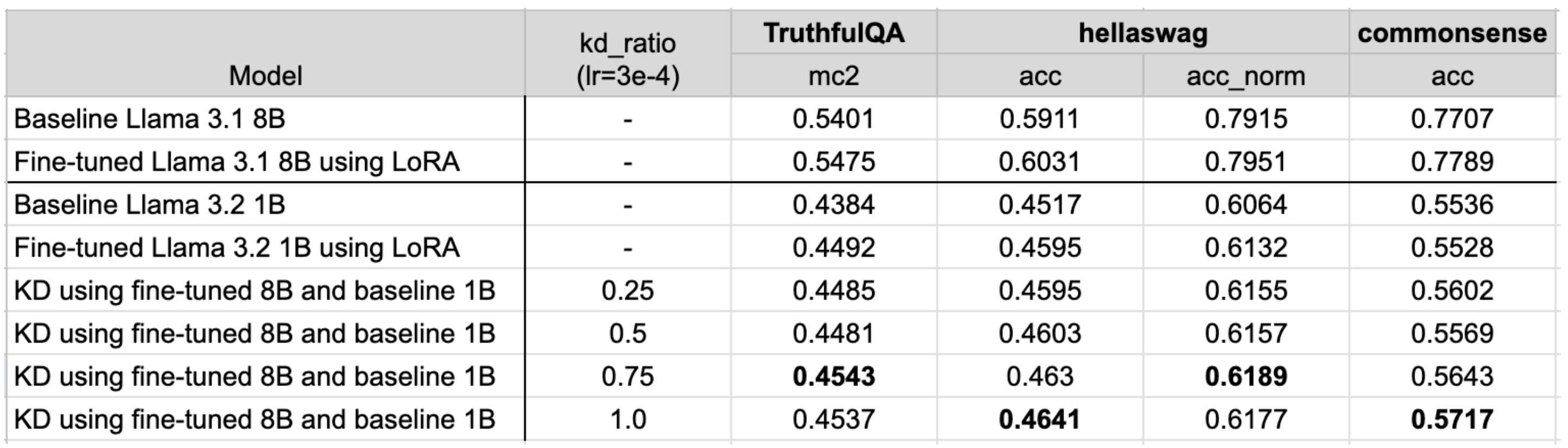
超参数调优:KD 比例¶
在配置中,我们将 kd_ratio 设置为 0.5,这意味着类别损失和知识蒸馏(KD)损失的权重相等。在这些实验中,我们研究了不同 KD 比例的影响,其中 0 表示仅使用类别损失,而 1 表示仅使用 KD 损失。
与调整学习率类似,KD 比例也可以通过以下方式进行调整:
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device kd_ratio=0.25
总体而言,较高的知识蒸馏比例对应的评估结果略优。
Qwen2 1.5B 到 0.5B¶
知识蒸馏(KD)配方也可以应用于不同的模型家族。在这里,我们探讨当教师模型和学生模型的参数数量更接近时,KD 的效果。在这个实验中,我们使用了 Qwen2 1.5B 和 Qwen2 0.5B 模型,其配置可以在 qwen2/knowledge_distillation_single_device 配置文件中找到。我们看到,仅在 alpaca 清洗数据集上进行训练只会提高 truthful_qa 的性能,而其他评估任务的指标则会下降。 对于 truthful_qa,KD 使学生模型的性能提升了 5.8%,而微调仅提升了 1.3%。