Pytorch深度学习框架概念¶
在这一节中,我们将学习TorchRec中的关键概念,这些概念旨在使用PyTorch优化大规模推荐系统。我们将详细学习每个概念的工作原理,并回顾其与其他TorchRec组件的结合方式。
TorchRec 的模块具有特定的输入/输出数据类型,以高效地表示稀疏特征,包括:
JaggedTensor: 一个用于单个稀疏特征的长度/偏移量和值张量的包装器。
KeyedJaggedTensor: 效率性地表示多个稀疏特征,可以将其视为多个
JaggedTensors。KeyedTensor: 一个围绕
torch.Tensor的包装器,允许通过键访问张量值。
为了高性能和效率,标准的
torch.Tensor 对表示稀疏数据来说非常低效。
TorchRec 引入了这些新的数据类型,因为它们提供了高效的
存储和稀疏输入数据的表示。正如您稍后会看到的那样,
KeyedJaggedTensor 使得在分布式环境中通信输入数据非常高效,
从而带来了 TorchRec 提供的关键性能优势之一。
在端到端的训练循环中,TorchRec 包含以下主要组件:
计划者: 接收嵌入表的配置、环境设置,并生成模型的优化分片计划。
分片器: 根据不同的分片策略(包括数据并行、表对表、行对行、表对行、列对列和表对列)按照分片计划对模型进行分片。
分布式模型并行: 结合分片器、优化器,并提供一个进入以分布式方式训练模型的入口点。
JaggedTensor¶
A JaggedTensor 代表通过长度、值和偏移量表示稀疏特征。它被称为“jagged”,因为它高效地表示具有可变长度序列的数据。相比之下,一个标准的torch.Tensor 假设每个序列具有相同的长度,这在现实世界的数据中通常不是这种情况。一个JaggedTensor 可以帮助表示此类数据而无需填充,使其非常高效。
关键组件:
Lengths: 一个表示每个实体元素数量的整数列表。Offsets: 一个整数列表,表示每个序列在展平值张量中的起始索引。这些提供了长度的替代方案。Values: 一个包含每个实体实际值的一维张量, 连续存储。
这是一个简单的示例,演示了每个组件会是什么样子:
# User interactions:
# - User 1 interacted with 2 items
# - User 2 interacted with 3 items
# - User 3 interacted with 1 item
lengths = [2, 3, 1]
offsets = [0, 2, 5] # Starting index of each user's interactions
values = torch.Tensor([101, 102, 201, 202, 203, 301]) # Item IDs interacted with
jt = JaggedTensor(lengths=lengths, values=values)
# OR
jt = JaggedTensor(offsets=offsets, values=values)
KeyedJaggedTensor¶
A KeyedJaggedTensor扩展了JaggedTensor的功能,通过引入键(通常是特征名称)来标记不同的特征组,例如用户特征和物品特征。这是在forward、EmbeddingBagCollection和EmbeddingCollection中使用的数据类型,因为它们用于表示表格中的多个特征。
A KeyedJaggedTensor 有一个隐含的批次大小,它是特征数量除以 lengths 张量的长度。下面的例子中批次大小为 2。类似于 JaggedTensor,offsets 和 lengths 的功能是相同的。你也可以通过从 KeyedJaggedTensor 中访问键来获取特征的 lengths、offsets 和 values。
keys = ["user_features", "item_features"]
# Lengths of interactions:
# - User features: 2 users, with 2 and 3 interactions respectively
# - Item features: 2 items, with 1 and 2 interactions respectively
lengths = [2, 3, 1, 2]
values = torch.Tensor([11, 12, 21, 22, 23, 101, 102, 201])
# Create a KeyedJaggedTensor
kjt = KeyedJaggedTensor(keys=keys, lengths=lengths, values=values)
# Access the features by key
print(kjt["user_features"])
# Outputs user features
print(kjt["item_features"])
计划器¶
TorchRec 规划器帮助确定模型的最佳分片配置。它评估多个分片嵌入表的可能性,并优化性能。规划器执行以下操作:
评估硬件的内存限制。
估计基于内存检索,例如嵌入查找。
处理数据特定因素。
考虑其他硬件特性,如带宽,来生成一个最优的分片计划。
为了确保准确考虑这些因素,规划者可以将嵌入表、约束条件、硬件信息和拓扑结构的数据纳入其中,以帮助生成最优的计划。
分布式嵌入表分割¶
TorchRec 分片器提供了多种分片策略,适用于各种使用场景。我们概述了一些分片策略及其工作原理、优点和局限性。一般来说,我们建议使用 TorchRec 规划器为您生成分片计划,因为它将为模型中的每个嵌入表找到最优的分片策略。
每个分片策略决定了如何进行表的分割,是否应该将表切开以及如何切,是否保留一些表的一份或几份,等等。从分片结果中每一份表(无论是单个嵌入表还是其一部分)都被称为一个分片。
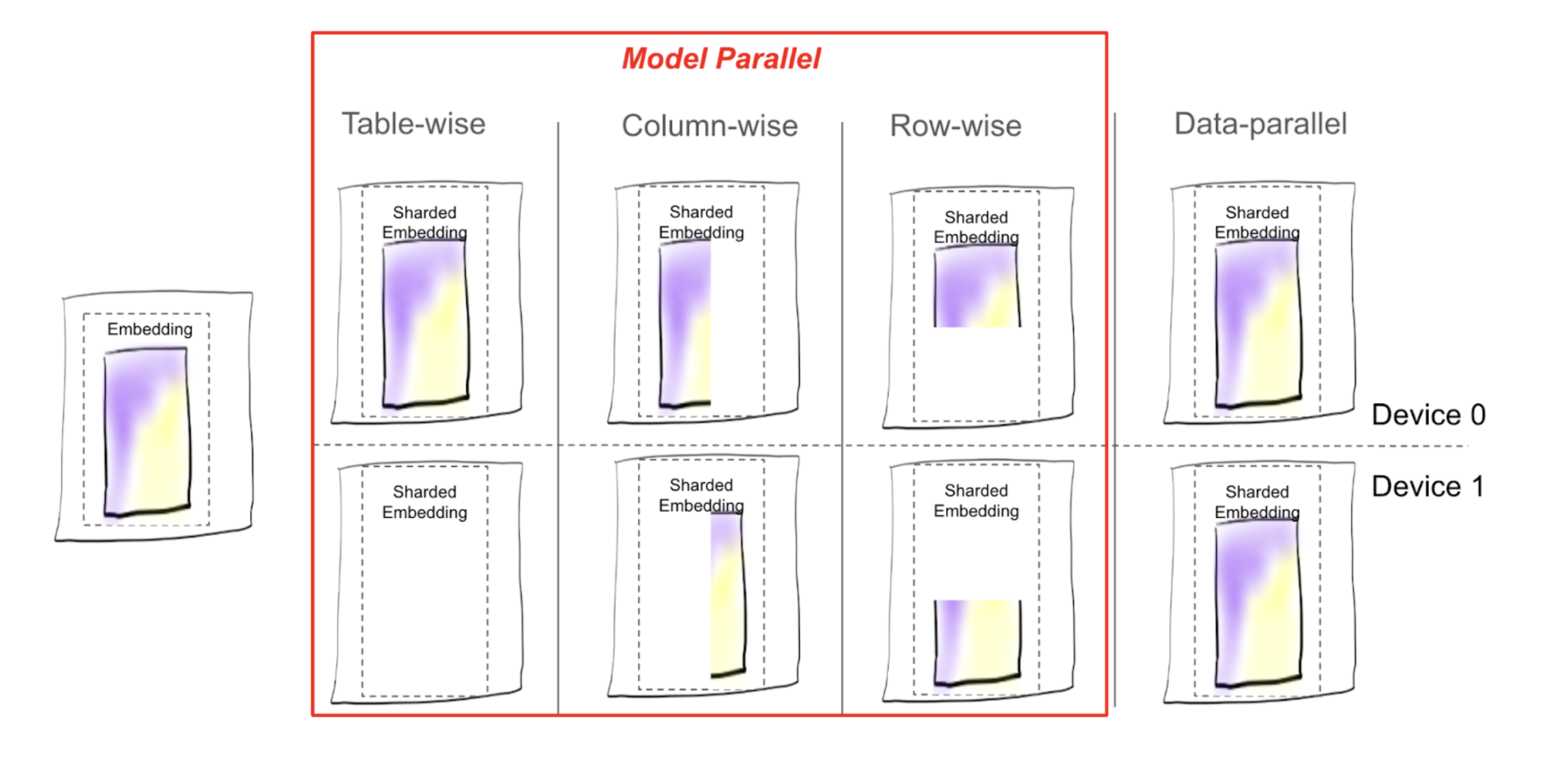
图1:可视化不同TorchRec提供的分片方案下表碎片的放置¶
这是TorchRec中可用的所有分片类型列表:
表对齐(TW):正如其名称所示,嵌入表格作为一个整体放在一个等级上。
列对齐 (CW): 表格沿
emb_dim维分块, 例如,emb_dim=256分成 4 个片段:[64, 64, 64, 64]。行对齐(RW):表格沿
hash_size维度分割, 通常均匀分配给所有排名。表对行对列(TWRW):表格放置在一个主机上,按行分配到该主机上的各个进程。
网格分片(GS):一张表被按时间窗口(CW)进行分片,每个时间窗口的分片都放置在主机上。
数据并行(DP):每个进程保留表的一个副本。
一旦被切片,模块将转换为它们的分片版本,称为ShardedEmbeddingCollection和ShardedEmbeddingBagCollection在TorchRec中。这些模块负责输入数据的通信、嵌入查找和梯度。
分布式训练与TorchRec分片模块¶
在许多分片策略可用的情况下,我们如何确定使用哪一个?每个分片方案都有成本,这与模型大小和GPU数量结合在一起,决定了哪个分片策略最适合模型。
不进行分片,每个GPU都保留着嵌入表的副本(DP),主要成本是计算,在前向传播中,每个GPU在内存中查找嵌入向量,并在反向传播中更新梯度。
在分片的情况下,会增加通信成本:每个GPU需要向其他GPU询问嵌入向量查找,并传递计算出的梯度。这通常被称为all2all通信。在TorchRec中,对于给定GPU上的输入数据,我们确定每个数据部分的嵌入分片位置并发送到目标GPU。目标GPU然后将嵌入向量返回到原始GPU。在反向传播过程中,梯度被发送回目标GPU,并根据优化器相应地更新分片。
如上所述,分片需要我们传递输入数据和嵌入查找。TorchRec 在三个主要阶段处理这一点,我们将将其称为用于训练和推理 TorchRec 模型的分片嵌入模块前向:
Feature 全对全/输入分布 (
input_dist)将输入数据(以
KeyedJaggedTensor的形式)传递给包含相关嵌入表分片的适当设备
嵌入查找
查找与新输入数据的嵌入,该数据是在所有特征交换后形成的
Embedding All to All/输出分布 (
output_dist)将嵌入式查找数据返回给请求该数据的适当设备(根据设备收到的输入数据)。
反向传播执行相同的操作,但顺序相反。
下面的图示展示了其工作原理:
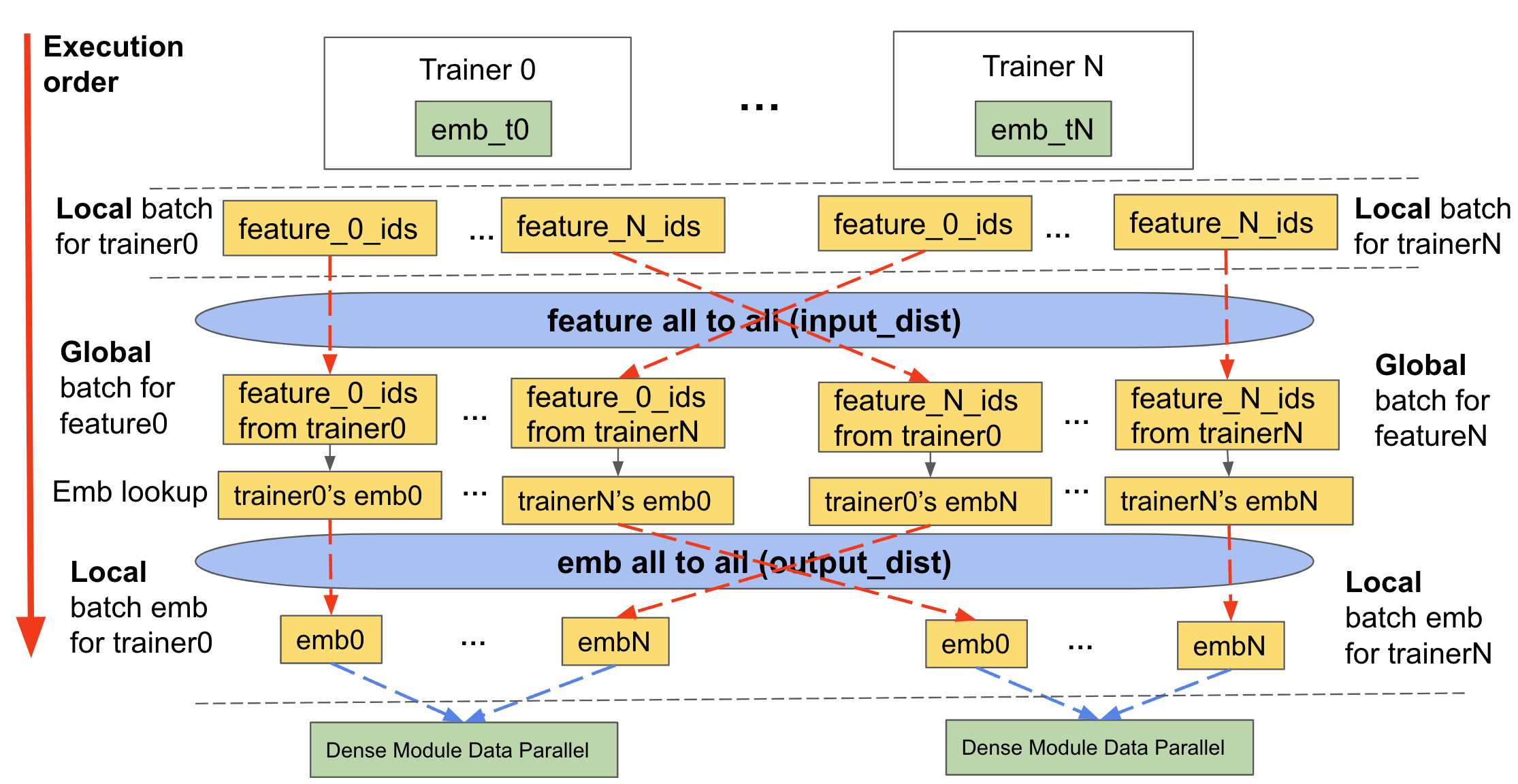
图2:表对齐分块表的前向传播,包括一个分块TorchRec模块的输入分布、查找和输出分布。¶
DistributedModelParallel¶
所有上述内容汇聚成TorchRec使用的主入口点,该入口点用于分割和整合计划。从宏观角度来看,
DistributedModelParallel 这个过程如下:
初始化环境,通过设置进程组和分配设备类型来完成。
使用默认着色器如果未提供着色器,包括默认的
EmbeddingBagCollectionSharder。输入提供的分片计划,如果没有提供,则生成一个。
创建模块的分片版本,并用它们替换原始模块,例如将
EmbeddingCollection转换为ShardedEmbeddingCollection。默认情况下,将
DistributedModelParallel与DistributedDataParallel包装起来,使模块同时具有模型和数据并行性。
优化器¶
TorchRec 模块提供了一个无缝的 API,可以将反向传播和优化步骤在训练过程中融合在一起,从而显著提高性能并减少内存使用,并且可以在分配不同的优化器到不同的模型参数时提供粒度。
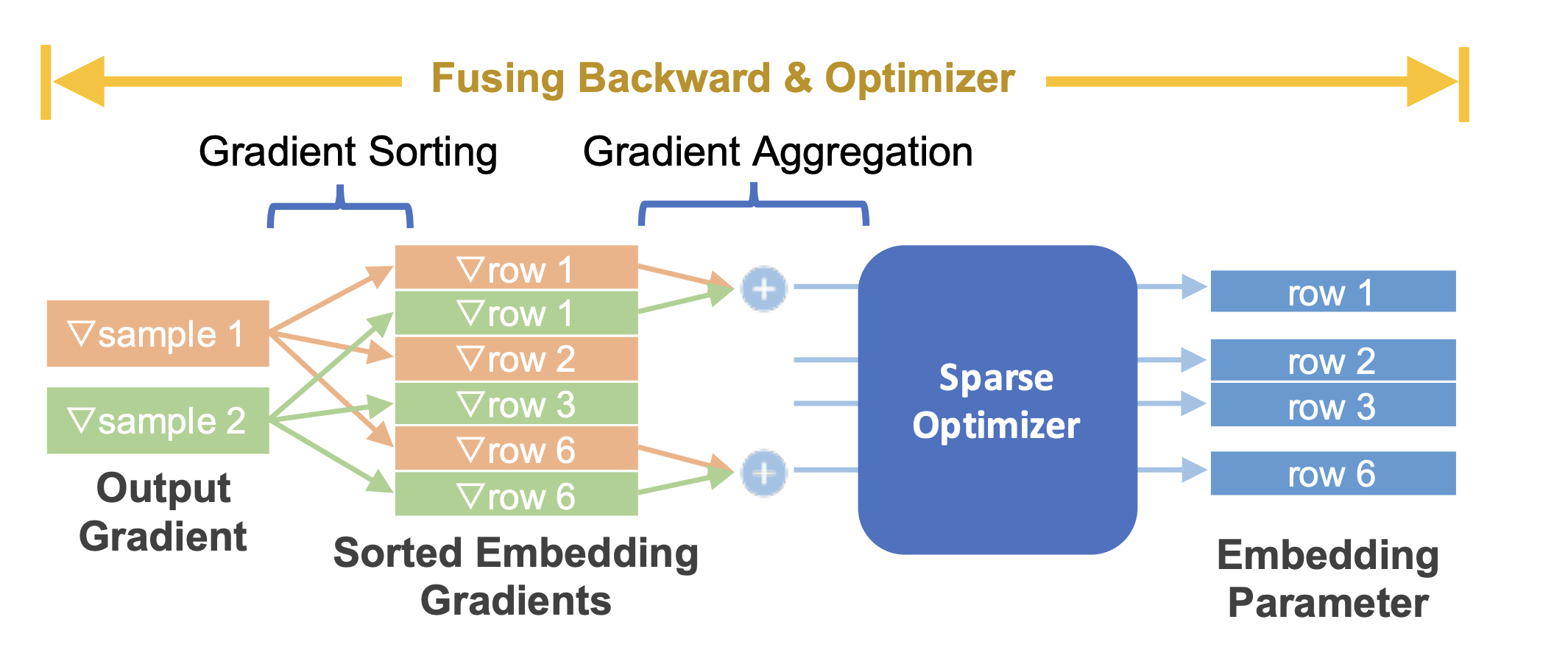
图3:将稀疏优化器与嵌入反向传播融合¶
推理¶
推理环境与训练环境不同,它们对性能和模型大小非常敏感。TorchRec 推理优化的两个关键差异是:
量化:推理模型被量化以降低延迟并减少模型大小。这种优化让我们尽可能少地使用设备进行推理以最小化延迟。
C++环境: 为了进一步减少延迟,模型在C++环境中运行。
TorchRec 提供以下功能,将 TorchRec 模型转换为推理可用:
模型量化API,包括自动优化FBGEMM TBE
分布式推理中的切分嵌入
将模型编译为TorchScript(兼容C++)