注意
转到末尾 以下载完整示例代码。
多智能体强化学习 (PPO) 使用 TorchRL 教程¶
作者: Matteo Bettini
另请参见
The BenchMARL 库提供了使用 TorchRL 的最新 MARL 算法实现。
本教程演示了如何使用PyTorch和torchrl来解决多智能体强化学习(MARL)问题。
为便于使用,本教程将遵循以下已提供教程的通用结构: 使用 TorchRL 进行强化学习(PPO)教程。 建议(但非必须)在开始本教程前先熟悉该教程。
在本教程中,我们将使用来自 VMAS, 一个多机器人模拟器,同样 基于PyTorch,在设备上运行并行批量仿真。
在 导航 环境中, 我们需要训练多个机器人(在随机位置生成), 使其导航至各自的目标(目标位置同样为随机生成),同时 使用 激光雷达(LIDAR)传感器 来避免彼此之间发生碰撞。
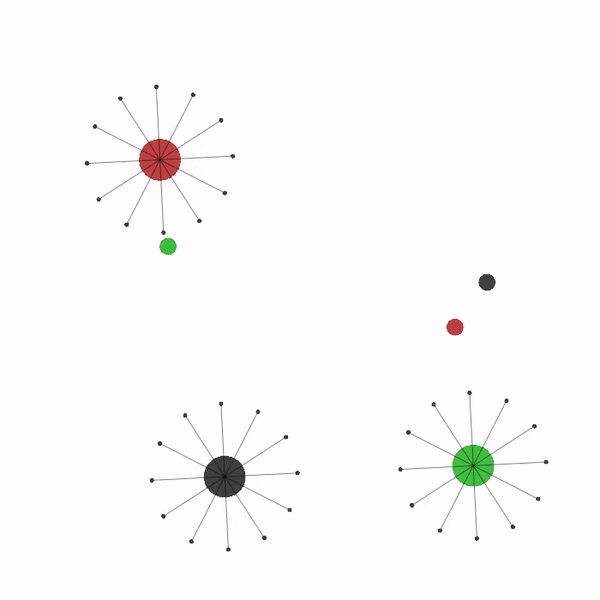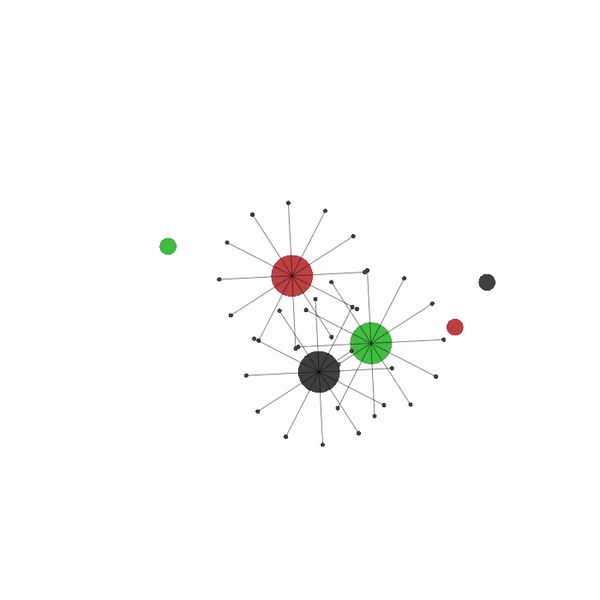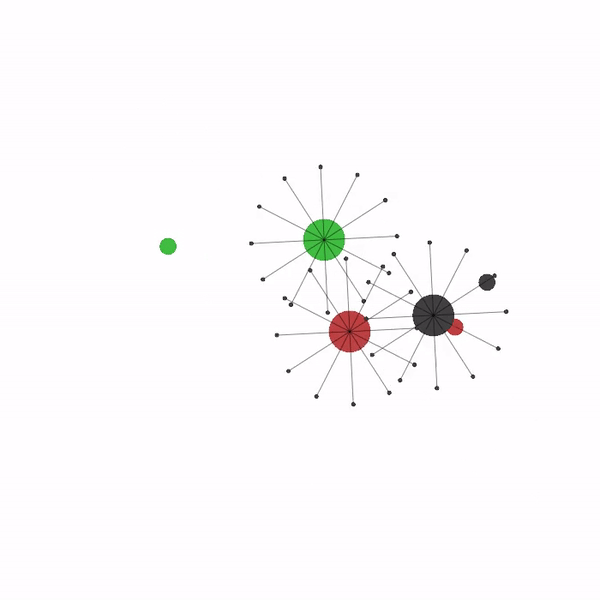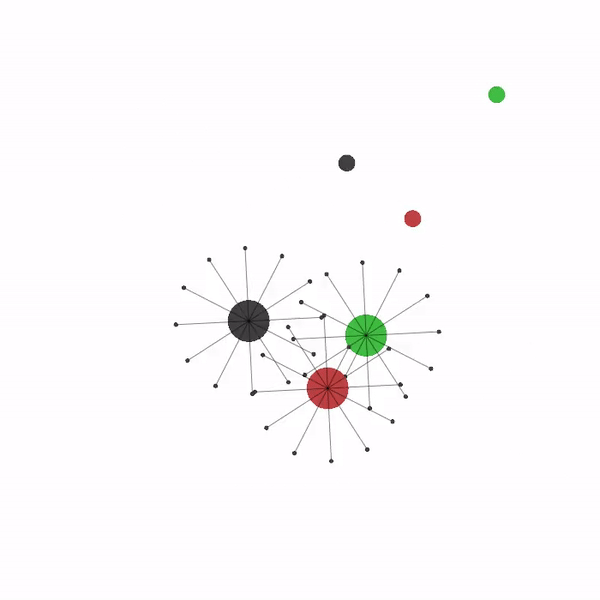
多智能体导航场景¶
核心收获:
如何在 TorchRL 中创建多智能体环境,其规格如何工作,以及它如何与库集成;
如何在 TorchRL 中使用 GPU 向量化环境;
如何在 TorchRL 中创建不同的多智能体网络架构(例如,使用参数共享、集中式评估器)
我们如何使用
tensordict.TensorDict来传输多智能体数据;我们如何将所有库组件(收集器、模块、重放缓冲区和损失函数)整合到多智能体MAPPO/IPPO训练循环中。
如果您在 Google Colab 中运行此代码,请确保安装以下依赖项:
!pip3 install torchrl
!pip3 install vmas
!pip3 install tqdm
Proximal Policy Optimization (PPO) 是一种策略梯度算法,其中收集一批数据并直接用于训练策略以最大化在某些接近性约束下的预期回报。你可以将其视为 REINFORCE 的复杂版本,REINFORCE 是基础的策略优化算法。更多信息,请参阅Proximal Policy Optimization Algorithms 论文。
这种类型的算法通常采用策略内训练。这意味着,在每次学习迭代中,我们都有一个采样和一个训练阶段。在迭代\(t\)的采样阶段,通过当前策略\(\mathbf{\pi}_t\)收集代理与环境交互的数据。 在训练阶段,所有收集到的数据立即被输入到训练过程中进行反向传播。这导致更新后的策略再次用于采样。 这个过程的循环执行构成了策略内学习。
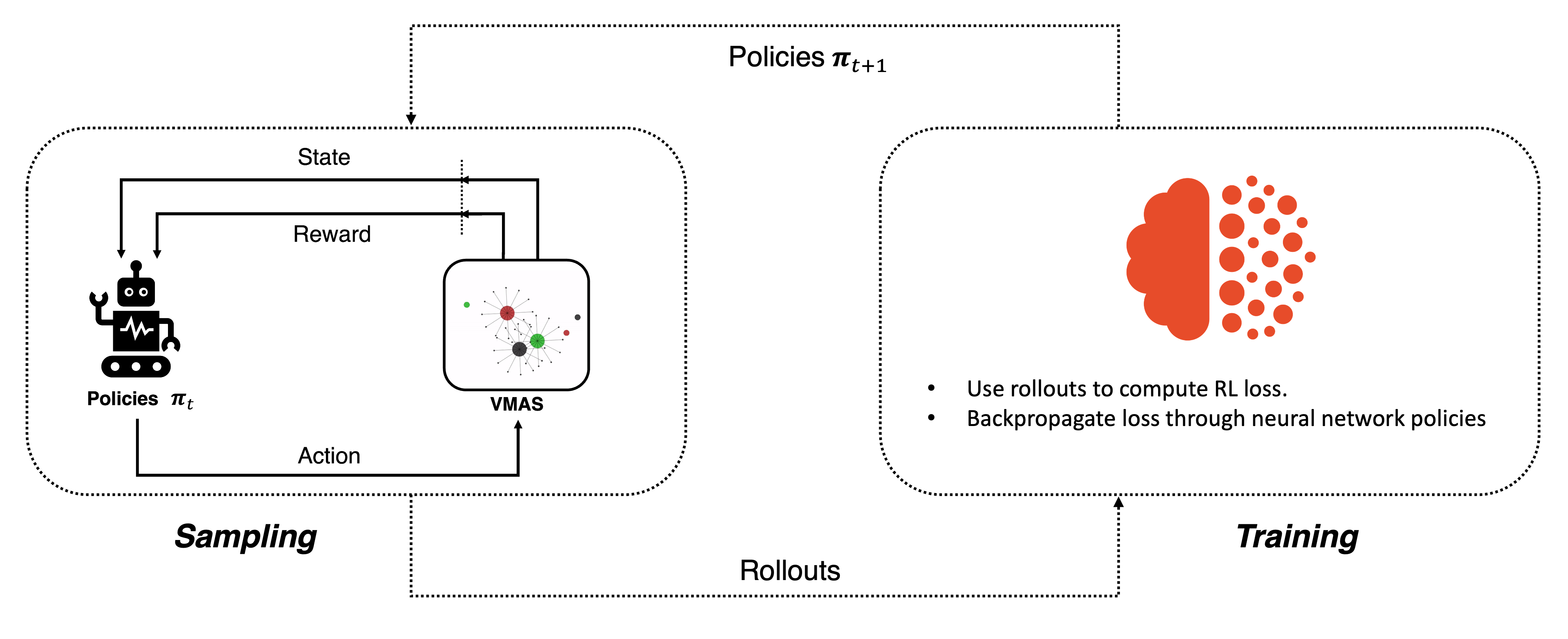
策略内学习¶
在PPO算法的训练阶段,使用一个评估器来估计策略采取的动作的好坏。评估器学习近似特定状态的价值(平均折扣回报)。然后,PPO损失将策略实际获得的回报与评估器估计的回报进行比较,以确定所采取动作的优势并指导策略优化。
在多智能体环境中,情况有所不同。我们现在有多个策略 \(\mathbf{\pi}\), 每个智能体一个。策略通常是局部的和分散的。这意味着 单个智能体的策略将根据其观察结果输出该智能体的动作。 在MARL文献中,这被称为 分散执行。 另一方面,对于评估器存在不同的公式,主要是:
在 MAPPO 中,评估器是集中式的,并将系统的全局状态作为输入。这可以是一个全局观察值,也可以是代理观察值的简单拼接。MAPPO 可以用于执行 集中式训练 的上下文中,因为它需要访问全局信息。
在 IPPO 中,评估器仅将相应代理的观察作为输入, 就像策略一样。这允许 分散式训练,因为评估器和策略都只需要本地 信息来计算它们的输出。
集中式评论器有助于克服多个智能体同时学习时带来的非平稳性问题,但另一方面,它们可能受其庞大输入空间的影响。 在本教程中,我们将能够训练这两种建模方式,并且还将讨论参数共享(即在各智能体之间共享网络参数的做法)对每种方式的影响。
本教程结构如下:
首先,我们将定义一组将要使用的超参数。
接下来,我们将使用 TorchRL 为 VMAS 模拟器提供的封装器,创建一个向量化多智能体环境。
接下来,我们将设计策略网络和评论家网络,并讨论各种选择对参数共享和评论家集中化的影响。
接下来,我们将创建采样收集器和重放缓冲区。
最后,我们将运行训练循环并分析结果。
如果你在 Colab 或带有图形用户界面(GUI)的机器上运行此程序,你还将能够渲染并可视化你自己训练的策略,包括训练前和训练后。
让我们导入我们的依赖项
# Torch
import torch
# Tensordict modules
from tensordict.nn import TensorDictModule
from tensordict.nn.distributions import NormalParamExtractor
from torch import multiprocessing
# Data collection
from torchrl.collectors import SyncDataCollector
from torchrl.data.replay_buffers import ReplayBuffer
from torchrl.data.replay_buffers.samplers import SamplerWithoutReplacement
from torchrl.data.replay_buffers.storages import LazyTensorStorage
# Env
from torchrl.envs import RewardSum, TransformedEnv
from torchrl.envs.libs.vmas import VmasEnv
from torchrl.envs.utils import check_env_specs
# Multi-agent network
from torchrl.modules import MultiAgentMLP, ProbabilisticActor, TanhNormal
# Loss
from torchrl.objectives import ClipPPOLoss, ValueEstimators
# Utils
torch.manual_seed(0)
from matplotlib import pyplot as plt
from tqdm import tqdm
定义超参数¶
我们为本教程设置了超参数。 根据可用的计算资源, 您可以选择在 GPU 或其他设备上运行策略和模拟器。 您可以调整其中部分值,以适应不同的计算需求。
# Devices
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
vmas_device = device # The device where the simulator is run (VMAS can run on GPU)
# Sampling
frames_per_batch = 6_000 # Number of team frames collected per training iteration
n_iters = 10 # Number of sampling and training iterations
total_frames = frames_per_batch * n_iters
# Training
num_epochs = 30 # Number of optimization steps per training iteration
minibatch_size = 400 # Size of the mini-batches in each optimization step
lr = 3e-4 # Learning rate
max_grad_norm = 1.0 # Maximum norm for the gradients
# PPO
clip_epsilon = 0.2 # clip value for PPO loss
gamma = 0.99 # discount factor
lmbda = 0.9 # lambda for generalised advantage estimation
entropy_eps = 1e-4 # coefficient of the entropy term in the PPO loss
环境¶
多智能体环境用于模拟多个智能体与环境的交互。 TorchRL API 支持集成多种类型的多智能体环境。 示例包括具有共享奖励或独立智能体奖励、统一/独立终止标志(done flags)以及统一/独立观测值的环境。 如需了解 TorchRL 中多智能体环境 API 的工作原理,请参阅专门的 文档章节。
VMAS模拟器,特别是针对具有个体奖励、信息、观察和动作的代理进行建模,但 具有一个集体完成标志。 此外,它使用向量化以批量方式执行模拟。 这意味着其所有状态和物理 都是PyTorch张量,第一个维度表示批次中并行环境的数量。 这使得可以利用GPU的单指令多数据(SIMD)范式,并通过利用GPU线程束中的并行化显著 加速并行计算。这也意味着, 在TorchRL中使用时,仿真和训练都可以在设备上运行,无需将数据传递到CPU。
我们今天要解决的多智能体任务是导航(参见上面的动画图)。 在导航中,随机生成的智能体 (带有周围点的圆圈)需要导航到 随机生成的目标(较小的圆圈)。 智能体需要使用激光雷达(它们周围的点)来 避免相互碰撞。 智能体在一个具有阻力和弹性碰撞的二维连续世界中行动。 它们的动作是二维连续力,决定了它们的加速度。 奖励由三个部分组成:碰撞惩罚、基于与目标距离的奖励以及所有智能体达到目标时的最终共享奖励。 基于距离的部分计算为两个连续时间步之间智能体与其目标之间的相对距离差。 每个智能体观察其位置、 速度、激光雷达读数以及相对于其目标的位置。
我们将现在实例化环境。
在这个教程中,我们将限制剧集数量为 max_steps,之后设置完成标志。这个功能已经在VMAS模拟器中提供,但也可以使用TorchRL StepCount
转换。我们还将使用 num_vmas_envs 矢量化环境,以利用批量模拟。
max_steps = 100 # Episode steps before done
num_vmas_envs = (
frames_per_batch // max_steps
) # Number of vectorized envs. frames_per_batch should be divisible by this number
scenario_name = "navigation"
n_agents = 3
env = VmasEnv(
scenario=scenario_name,
num_envs=num_vmas_envs,
continuous_actions=True, # VMAS supports both continuous and discrete actions
max_steps=max_steps,
device=vmas_device,
# Scenario kwargs
n_agents=n_agents, # These are custom kwargs that change for each VMAS scenario, see the VMAS repo to know more.
)
环境不仅由其模拟器和转换定义,还包括一系列描述在执行期间可以预期的元数据。
为了提高效率,TorchRL 对环境规格的要求相当严格,但你可以轻松检查你的环境规格是否合适。
在我们的示例中,VmasEnv 负责为你的环境设置正确的规格,因此你不需要关心这一点。
有四个规格需要查看:
action_spec定义了动作空间;reward_spec定义奖励域;done_spec定义完成域;observation_spec定义了环境步骤中所有其他输出的域;
print("action_spec:", env.full_action_spec)
print("reward_spec:", env.full_reward_spec)
print("done_spec:", env.full_done_spec)
print("observation_spec:", env.observation_spec)
action_spec: CompositeSpec(
agents: CompositeSpec(
action: BoundedTensorSpec(
shape=torch.Size([60, 3, 2]),
space=ContinuousBox(
low=Tensor(shape=torch.Size([60, 3, 2]), device=cpu, dtype=torch.float32, contiguous=True),
high=Tensor(shape=torch.Size([60, 3, 2]), device=cpu, dtype=torch.float32, contiguous=True)),
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([60, 3])),
device=cpu,
shape=torch.Size([60]))
reward_spec: CompositeSpec(
agents: CompositeSpec(
reward: UnboundedContinuousTensorSpec(
shape=torch.Size([60, 3, 1]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([60, 3])),
device=cpu,
shape=torch.Size([60]))
done_spec: CompositeSpec(
done: DiscreteTensorSpec(
shape=torch.Size([60, 1]),
space=DiscreteBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
terminated: DiscreteTensorSpec(
shape=torch.Size([60, 1]),
space=DiscreteBox(n=2),
device=cpu,
dtype=torch.bool,
domain=discrete),
device=cpu,
shape=torch.Size([60]))
observation_spec: CompositeSpec(
agents: CompositeSpec(
observation: UnboundedContinuousTensorSpec(
shape=torch.Size([60, 3, 18]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
info: CompositeSpec(
pos_rew: UnboundedContinuousTensorSpec(
shape=torch.Size([60, 3, 1]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
final_rew: UnboundedContinuousTensorSpec(
shape=torch.Size([60, 3, 1]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
agent_collisions: UnboundedContinuousTensorSpec(
shape=torch.Size([60, 3, 1]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
device=cpu,
shape=torch.Size([60, 3])),
device=cpu,
shape=torch.Size([60, 3])),
device=cpu,
shape=torch.Size([60]))
使用上述命令,我们可以访问每个值的域。
通过这样做,我们可以看到除了 done 之外的所有规格都有一个前导形状 (num_vmas_envs, n_agents)。
这表示这些值将在每个代理和每个单独环境中存在。
另一方面,done 规格具有前导形状 num_vmas_envs,表示 done 是在代理之间共享的。
TorchRL 提供了一种机制,用于追踪哪些多智能体强化学习(MARL)规格是共享的,哪些不是。 事实上,具有额外智能体维度的规格(即,这些规格对每个智能体均不相同)将被包含在内部的 “agents” 键中。
如您所见,奖励(reward)和动作(action)规范中均包含“agent”键, 这意味着属于这些规范的张量字典(tensordict)中的条目将嵌套在一个名为“agents”的张量字典中, 从而将所有与各智能体(agent)相关的值归为一组。
为快速获取张量字典(tensordict)中每个值对应的键,我们只需向环境查询相应的键, 即可立即明确哪些键是按智能体(per-agent)划分的,哪些是共享的(shared)。 该信息将有助于告知 TorchRL 的其他所有组件:每个值应从何处获取。
print("action_keys:", env.action_keys)
print("reward_keys:", env.reward_keys)
print("done_keys:", env.done_keys)
action_keys: [('agents', 'action')]
reward_keys: [('agents', 'reward')]
done_keys: ['done', 'terminated']
变换¶
我们可以向环境追加所需的任意 TorchRL 变换。 这些变换将以某种期望的方式修改环境的输入/输出。 需要强调的是,在多智能体场景中,必须显式地指定待修改的键(keys)。
例如,在这种情况下,我们将实例化一个RewardSum变换,它将在整个回合中累加奖励。
我们将告诉这个变换在哪里找到奖励键以及在哪里写入累加的回合奖励。
转换后的环境将继承
包装环境的设备和元数据,并根据其包含的变换序列进行转换。
env = TransformedEnv(
env,
RewardSum(in_keys=[env.reward_key], out_keys=[("agents", "episode_reward")]),
)
the check_env_specs() 函数运行一个小规模滚动并将其输出与环境规范进行比较。如果没有错误抛出,我们可以确信规范已经正确定义:
check_env_specs(env)
展开¶
为了好玩,让我们看看一个简单的随机展开是什么样子。你可以调用 env.rollout(n_steps) 并获得环境输入和输出的概览。动作将自动从动作规范域中随机抽取。
n_rollout_steps = 5
rollout = env.rollout(n_rollout_steps)
print("rollout of three steps:", rollout)
print("Shape of the rollout TensorDict:", rollout.batch_size)
rollout of three steps: TensorDict(
fields={
agents: TensorDict(
fields={
action: Tensor(shape=torch.Size([60, 5, 3, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
info: TensorDict(
fields={
agent_collisions: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
final_rew: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
pos_rew: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 5, 3]),
device=cpu,
is_shared=False),
observation: Tensor(shape=torch.Size([60, 5, 3, 18]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 5, 3]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([60, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
agents: TensorDict(
fields={
episode_reward: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
info: TensorDict(
fields={
agent_collisions: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
final_rew: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
pos_rew: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 5, 3]),
device=cpu,
is_shared=False),
observation: Tensor(shape=torch.Size([60, 5, 3, 18]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([60, 5, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 5, 3]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([60, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([60, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([60, 5]),
device=cpu,
is_shared=False),
terminated: Tensor(shape=torch.Size([60, 5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([60, 5]),
device=cpu,
is_shared=False)
Shape of the rollout TensorDict: torch.Size([60, 5])
我们可以看到我们的展开有 batch_size 个 (num_vmas_envs, n_rollout_steps)。
这意味着其中的所有张量都将具有这些前导维度。
深入观察,我们可以看到输出的张量字典可以按以下方式划分:
在根目录 (通过运行
rollout.exclude("next")可访问) 我们将找到所有在第一次调用重置后可用的键。我们可以通过索引n_rollout_steps维度来查看它们在展开步骤中的演变。在这些键中,我们将找到每个代理在rollout["agents"]tensordict 中不同的键,这将具有批量大小(num_vmas_envs, n_rollout_steps, n_agents)表示它正在存储额外的代理维度。在这个代理 tensordict 之外的将是共享的键(在这种情况下只有 done)。在下一步 (通过运行
rollout.get("next")可访问)。我们将找到与根相同的结构, 但仅对于在一步之后可用的键。
在 TorchRL 中,约定是:`done`(完成标志)和观测值(observations)同时存在于 `root` 和 `next` 中(因为它们在环境重置时和执行一步操作后均可用)。而动作(action)仅存在于 `root` 中(因为执行一步操作本身不会产生新的动作),奖励(reward)仅存在于 `next` 中(因为在环境重置时没有奖励)。 该结构遵循《强化学习导论》(Sutton 与 Barto 著)中的表示方式,其中 `root` 表示世界步长中时间点 \(t\) 的数据,而 `next` 表示时间点 \(t+1\) 的数据。
渲染随机回放¶
如果你使用的是 Google Colab,或在一台装有 OpenGL 和图形用户界面(GUI)的机器上运行,你实际上可以渲染一次随机策略的轨迹(rollout)。 这将帮助你了解随机策略在此任务中所能达到的效果,以便与你自己训练的策略进行对比!
要渲染一个回放,请遵循本教程末尾渲染部分中的说明
并只需删除 policy=policy 从 env.rollout() 。
政策¶
PPO 使用随机策略来处理探索。这意味着我们的神经网络需要输出某个分布的参数,而不是直接输出与所采取动作相对应的单一数值。
由于数据是连续的,我们使用 Tanh-Normal 分布来满足动作空间的边界约束。TorchRL 提供了此类分布,而我们唯一需要关注的是构建一个能输出正确参数数量的神经网络。
在这种情况下,每个代理的动作将由一个二维独立正态分布表示。
为此,我们的神经网络将必须为每个动作输出一个均值和一个标准差。
因此,每个代理将有2 * n_actions_per_agents个输出。
另一个重要的决定是我们是否希望我们的智能体共享策略参数。 一方面,共享参数意味着它们将共享相同的策略,这将使它们能够从彼此的经验中受益。这也将导致更快的训练。 另一方面,这将使它们的行为同质化,因为它们实际上共享相同的模型。 在这个例子中,我们将启用共享,因为我们不介意同质性,并且可以从计算速度中受益,但在自己的问题中始终要考虑这个决定!
我们分三个步骤设计策略。
首先: 定义一个神经网络 n_obs_per_agent -> 2 * n_actions_per_agents
为此我们使用MultiAgentMLP,一个专门为多个代理设计的TorchRL模块,提供了许多自定义选项。
share_parameters_policy = True
policy_net = torch.nn.Sequential(
MultiAgentMLP(
n_agent_inputs=env.observation_spec["agents", "observation"].shape[
-1
], # n_obs_per_agent
n_agent_outputs=2 * env.action_spec.shape[-1], # 2 * n_actions_per_agents
n_agents=env.n_agents,
centralised=False, # the policies are decentralised (ie each agent will act from its observation)
share_params=share_parameters_policy,
device=device,
depth=2,
num_cells=256,
activation_class=torch.nn.Tanh,
),
NormalParamExtractor(), # this will just separate the last dimension into two outputs: a loc and a non-negative scale
)
第二: 将神经网络封装在一个 TensorDictModule
这是一个简单的模块,它将从tensordict中读取in_keys,将其输入神经网络,并将输出原地写入out_keys。
请注意,我们使用 ("agents", ...) 个键,因为这些键表示具有额外 n_agents 维度的数据。
policy_module = TensorDictModule(
policy_net,
in_keys=[("agents", "observation")],
out_keys=[("agents", "loc"), ("agents", "scale")],
)
第三: 将 TensorDictModule 包裹在一个 ProbabilisticActor 中
我们现在需要根据正态分布的位置和尺度构建一个分布。为此,我们指示ProbabilisticActor类根据位置和尺度参数构建一个TanhNormal。我们还提供了这个分布的最小值和最大值,这些值是从环境规格中收集的。
名称必须以in_keys(因此从上面的TensorDictModule中得到的out_keys的名称也必须以TanhNormal分布构造函数的关键字参数(loc 和 scale)结尾。
policy = ProbabilisticActor(
module=policy_module,
spec=env.unbatched_action_spec,
in_keys=[("agents", "loc"), ("agents", "scale")],
out_keys=[env.action_key],
distribution_class=TanhNormal,
distribution_kwargs={
"low": env.unbatched_action_spec[env.action_key].space.low,
"high": env.unbatched_action_spec[env.action_key].space.high,
},
return_log_prob=True,
log_prob_key=("agents", "sample_log_prob"),
) # we'll need the log-prob for the PPO loss
评估网络¶
评论网络(Critic Network)是近端策略优化(PPO)算法的关键组成部分,尽管它在采样阶段并不被使用。该模块将读取观测值,并返回对应的状态价值估计。
如前所述,应仔细考虑是否共享判别器参数。 一般来说,参数共享将加快训练收敛速度,但有几个重要的注意事项:
当智能体具有不同的奖励函数时,不建议共享(网络参数),因为评论家需要学习为同一状态分配不同的价值(例如,在混合协作-竞争环境中)。
在去中心化训练环境中,若无额外的基础设施来同步参数,则无法执行共享操作。
在所有其他情况下,当奖励函数(需区别于奖励本身)对所有智能体都相同时(如当前场景所示),共享参数可带来性能提升。但这可能以智能体策略同质化为代价。 通常,判断哪种选择更优的最佳方式是快速对两种方案均进行实验。
这里也是我们选择 MAPPO 和 IPPO 的地方:
借助MAPPO,我们将获得一个具备全局观察能力的中心化评论家(即:它将以所有智能体观测值的拼接结果作为输入)。 我们之所以能够这样做,是因为我们处于仿真环境中,且训练过程是集中式的。
有了IPPO,我们将拥有一个本地分散的评估器,就像策略一样。
在任何情况下,评论者的输出将具有形状 (..., n_agents, 1)。
如果评论者是集中且共享的,
则沿 n_agents 维的所有值都将相同。
share_parameters_critic = True
mappo = True # IPPO if False
critic_net = MultiAgentMLP(
n_agent_inputs=env.observation_spec["agents", "observation"].shape[-1],
n_agent_outputs=1, # 1 value per agent
n_agents=env.n_agents,
centralised=mappo,
share_params=share_parameters_critic,
device=device,
depth=2,
num_cells=256,
activation_class=torch.nn.Tanh,
)
critic = TensorDictModule(
module=critic_net,
in_keys=[("agents", "observation")],
out_keys=[("agents", "state_value")],
)
让我们尝试我们的策略和评估模块。正如前面提到的,使用
TensorDictModule 可以直接读取环境的输出来运行这些模块,因为它们知道要读取哪些信息以及在哪里写入:
从这一点开始,多智能体专用组件已经实例化,我们将直接沿用单智能体学习中使用的相同组件。这难道不令人兴奋吗?
print("Running policy:", policy(env.reset()))
print("Running value:", critic(env.reset()))
Running policy: TensorDict(
fields={
agents: TensorDict(
fields={
action: Tensor(shape=torch.Size([60, 3, 2]), device=cpu, dtype=torch.float32, is_shared=False),
episode_reward: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
info: TensorDict(
fields={
agent_collisions: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
final_rew: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
pos_rew: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 3]),
device=cpu,
is_shared=False),
loc: Tensor(shape=torch.Size([60, 3, 2]), device=cpu, dtype=torch.float32, is_shared=False),
observation: Tensor(shape=torch.Size([60, 3, 18]), device=cpu, dtype=torch.float32, is_shared=False),
sample_log_prob: Tensor(shape=torch.Size([60, 3]), device=cpu, dtype=torch.float32, is_shared=False),
scale: Tensor(shape=torch.Size([60, 3, 2]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 3]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([60, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([60, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([60]),
device=cpu,
is_shared=False)
Running value: TensorDict(
fields={
agents: TensorDict(
fields={
episode_reward: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
info: TensorDict(
fields={
agent_collisions: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
final_rew: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False),
pos_rew: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 3]),
device=cpu,
is_shared=False),
observation: Tensor(shape=torch.Size([60, 3, 18]), device=cpu, dtype=torch.float32, is_shared=False),
state_value: Tensor(shape=torch.Size([60, 3, 1]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([60, 3]),
device=cpu,
is_shared=False),
done: Tensor(shape=torch.Size([60, 1]), device=cpu, dtype=torch.bool, is_shared=False),
terminated: Tensor(shape=torch.Size([60, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([60]),
device=cpu,
is_shared=False)
数据收集器¶
TorchRL 提供了一组数据收集器类。简而言之,这些类执行三项操作:重置环境、利用策略和最新观测值计算动作、在环境中执行一步操作,并重复后两个步骤,直至环境发出停止信号(或达到“完成”状态)。
我们将使用最简单的数据收集器,其输出与环境 rollout 相同, 唯一的区别在于:该收集器会在达到所需帧数之前自动重置已完成(done)的状态。
collector = SyncDataCollector(
env,
policy,
device=vmas_device,
storing_device=device,
frames_per_batch=frames_per_batch,
total_frames=total_frames,
)
回放缓冲区¶
经验回放缓冲区(Replay buffers)是无策略(off-policy)强化学习算法中常见的组成部分。 在有策略(on-policy)场景中,每次收集一批数据后都会重新填充经验回放缓冲区,且其数据会在一定数量的训练轮次(epochs)内被反复使用。
对PPO使用经验回放缓冲区(replay buffer)并非必需,我们完全可以在线直接使用所收集的数据;但使用这些类能够帮助我们以可复现的方式轻松构建内部训练循环。
损失函数¶
为方便起见,PPO 损失函数可直接从 TorchRL 导入,使用的是
ClipPPOLoss 类。这是使用 PPO 的最简单方式:
它隐藏了 PPO 的数学运算以及与之相关的控制流程。
PPO 需要计算一些“优势估计”。简而言之,优势是一个值,反映了在处理偏差/方差权衡时对回报值的期望。
为了计算优势,只需要(1)构建优势模块,该模块利用我们的价值算子,并且(2)在每个周期之前将每批数据通过它。
GAE 模块将更新输入 TensorDict 中的新 "advantage" 和 "value_target" 条目。
"value_target" 是一个无梯度张量,表示价值网络应使用输入观察值表示的经验值。
这两个都将被 ClipPPOLoss 用于返回策略和价值损失。
loss_module = ClipPPOLoss(
actor_network=policy,
critic_network=critic,
clip_epsilon=clip_epsilon,
entropy_coef=entropy_eps,
normalize_advantage=False, # Important to avoid normalizing across the agent dimension
)
loss_module.set_keys( # We have to tell the loss where to find the keys
reward=env.reward_key,
action=env.action_key,
sample_log_prob=("agents", "sample_log_prob"),
value=("agents", "state_value"),
# These last 2 keys will be expanded to match the reward shape
done=("agents", "done"),
terminated=("agents", "terminated"),
)
loss_module.make_value_estimator(
ValueEstimators.GAE, gamma=gamma, lmbda=lmbda
) # We build GAE
GAE = loss_module.value_estimator
optim = torch.optim.Adam(loss_module.parameters(), lr)
训练循环¶
现在,我们已具备编写训练循环所需的全部要素。 步骤包括:
- Collect data
- Compute advantage
- Loop over epochs
- Loop over minibatches to compute loss values
反向传播
优化
重复
重复
重复
重复
pbar = tqdm(total=n_iters, desc="episode_reward_mean = 0")
episode_reward_mean_list = []
for tensordict_data in collector:
tensordict_data.set(
("next", "agents", "done"),
tensordict_data.get(("next", "done"))
.unsqueeze(-1)
.expand(tensordict_data.get_item_shape(("next", env.reward_key))),
)
tensordict_data.set(
("next", "agents", "terminated"),
tensordict_data.get(("next", "terminated"))
.unsqueeze(-1)
.expand(tensordict_data.get_item_shape(("next", env.reward_key))),
)
# We need to expand the done and terminated to match the reward shape (this is expected by the value estimator)
with torch.no_grad():
GAE(
tensordict_data,
params=loss_module.critic_network_params,
target_params=loss_module.target_critic_network_params,
) # Compute GAE and add it to the data
data_view = tensordict_data.reshape(-1) # Flatten the batch size to shuffle data
replay_buffer.extend(data_view)
for _ in range(num_epochs):
for _ in range(frames_per_batch // minibatch_size):
subdata = replay_buffer.sample()
loss_vals = loss_module(subdata)
loss_value = (
loss_vals["loss_objective"]
+ loss_vals["loss_critic"]
+ loss_vals["loss_entropy"]
)
loss_value.backward()
torch.nn.utils.clip_grad_norm_(
loss_module.parameters(), max_grad_norm
) # Optional
optim.step()
optim.zero_grad()
collector.update_policy_weights_()
# Logging
done = tensordict_data.get(("next", "agents", "done"))
episode_reward_mean = (
tensordict_data.get(("next", "agents", "episode_reward"))[done].mean().item()
)
episode_reward_mean_list.append(episode_reward_mean)
pbar.set_description(f"episode_reward_mean = {episode_reward_mean}", refresh=False)
pbar.update()
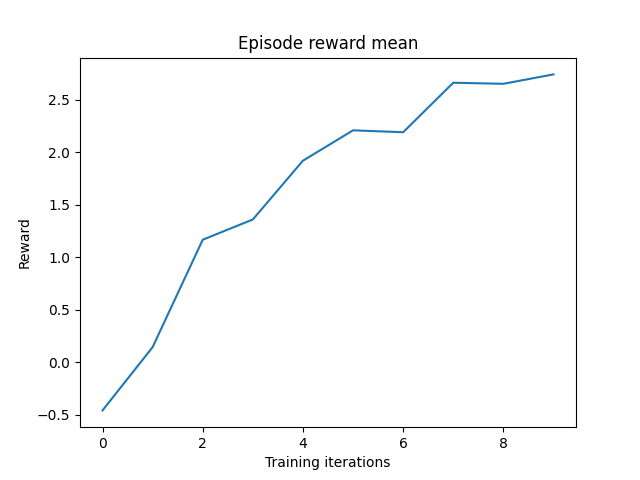
episode_reward_mean = 0: 0%| | 0/10 [00:00<?, ?it/s]
episode_reward_mean = -0.4579917788505554: 10%|█ | 1/10 [00:06<01:01, 6.78s/it]
episode_reward_mean = 0.14524875581264496: 20%|██ | 2/10 [00:13<00:54, 6.79s/it]
episode_reward_mean = 1.168386459350586: 30%|███ | 3/10 [00:20<00:47, 6.75s/it]
episode_reward_mean = 1.3613134622573853: 40%|████ | 4/10 [00:27<00:40, 6.75s/it]
episode_reward_mean = 1.921463131904602: 50%|█████ | 5/10 [00:33<00:33, 6.75s/it]
episode_reward_mean = 2.2106335163116455: 60%|██████ | 6/10 [00:40<00:26, 6.73s/it]
episode_reward_mean = 2.1925103664398193: 70%|███████ | 7/10 [00:47<00:20, 6.76s/it]
episode_reward_mean = 2.664064407348633: 80%|████████ | 8/10 [00:54<00:13, 6.80s/it]
episode_reward_mean = 2.6539173126220703: 90%|█████████ | 9/10 [01:01<00:06, 6.85s/it]
episode_reward_mean = 2.743558168411255: 100%|██████████| 10/10 [01:08<00:00, 6.90s/it]
结果¶
让我们绘制每集获得的平均奖励
为了使训练持续更长时间,请增加n_iters超参数。
plt.plot(episode_reward_mean_list)
plt.xlabel("Training iterations")
plt.ylabel("Reward")
plt.title("Episode reward mean")
plt.show()
渲染¶
如果您在带有图形用户界面的机器上运行此操作,可以通过运行以下命令来渲染训练好的策略:
with torch.no_grad():
env.rollout(
max_steps=max_steps,
policy=policy,
callback=lambda env, _: env.render(),
auto_cast_to_device=True,
break_when_any_done=False,
)
如果您在Google Colab中运行此代码,可以通过运行以下命令来渲染训练好的策略:
!apt-get update
!apt-get install -y x11-utils
!apt-get install -y xvfb
!pip install pyvirtualdisplay
import pyvirtualdisplay
display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
display.start()
from PIL import Image
def rendering_callback(env, td):
env.frames.append(Image.fromarray(env.render(mode="rgb_array")))
env.frames = []
with torch.no_grad():
env.rollout(
max_steps=max_steps,
policy=policy,
callback=rendering_callback,
auto_cast_to_device=True,
break_when_any_done=False,
)
env.frames[0].save(
f"{scenario_name}.gif",
save_all=True,
append_images=env.frames[1:],
duration=3,
loop=0,
)
from IPython.display import Image
Image(open(f"{scenario_name}.gif", "rb").read())
结论和下一步¶
在这个教程中,我们已经看到了:
如何在 TorchRL 中创建多智能体环境,其规格如何工作,以及它如何与库集成;
如何在 TorchRL 中使用 GPU 向量化环境;
如何在 TorchRL 中创建不同的多智能体网络架构(例如,使用参数共享、集中式评估器)
我们如何使用
tensordict.TensorDict来传输多智能体数据;我们如何将所有库组件(收集器、模块、重放缓冲区和损失函数)整合到多智能体MAPPO/IPPO训练循环中。
现在,您已经熟练掌握了多智能体 DDPG,可以前往 GitHub 仓库查看 TorchRL 提供的所有多智能体实现。 这些是许多主流多智能体强化学习(MARL)算法的纯代码脚本,例如本教程中介绍的算法、QMIX、MADDPG、IQL,以及更多!
您还可以查看我们的另一篇多智能体教程,了解如何在 PettingZoo/VMAS 中使用多个智能体组训练竞争性 MADDPG/IDDPG: 使用 TorchRL 进行竞争性多智能体强化学习(DDPG)教程。
如果您有兴趣在 TorchRL 中创建或封装自己的多智能体环境, 可以查看专门的 文档章节。
最后,您可以修改本教程的参数,尝试许多其他配置和场景,从而成为多智能体强化学习(MARL)专家。 以下是您可以在 VMAS 中尝试的一些可能场景的视频。

脚本总运行时间: (2 分钟 4.311 秒)
估计内存使用量: 319 MB