模型并行¶
Pipeline 并行最初在 Gpipe 论文中提出,是一种在多个 GPU 上训练大型模型的高效技术。
警告
torch.distributed.pipeline 已弃用,因此本文档也已弃用。有关最新的流水线并行实现,请参阅 PyTorch 组织下的 PiPPy 库(PyTorch 的流水线并行)。
使用多个GPU的模型并行¶
通常对于无法在单个GPU上运行的大模型,会采用模型并行的方法,将模型的某些部分放置在不同的GPU上。然而,如果对顺序模型简单地进行这种处理,训练过程会由于GPU利用率低下而受到影响,因为在某一时刻只有一个GPU处于活跃状态,如下图所示:
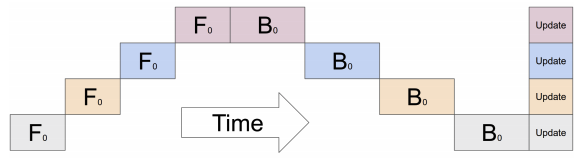
管道化执行¶
为了解决这个问题,管道并行将输入的小批量数据拆分为多个微小批量,并在多个 GPU 上流水线式地执行这些微小批量。如下图所示:
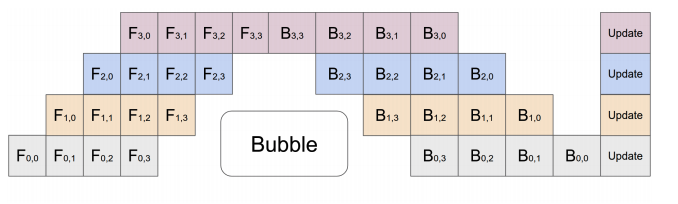
PyTorch中的Pipe API¶
- class torch.distributed.pipeline.sync.Pipe(module, chunks=1, checkpoint='except_last', deferred_batch_norm=False)[source]¶
将任意的
nn.Sequential模块封装起来, 使用同步管道并行进行训练。如果该模块需要大量内存且无法在单个GPU上运行, 管道并行是一种有用的训练技术。该实现基于 torchgpipe 论文。
Pipe 将管道并行与检查点技术相结合,以在尽量减少设备利用率不足的同时降低训练所需的峰值内存。
您应该将所有模块放置在适当的设备上,并将其封装到一个
nn.Sequential模块中,以定义所需的执行顺序。如果某个模块不包含任何参数/缓冲区,则假定该模块应在 CPU 上执行,并且在执行之前,传递给该模块的适当输入张量会被移动到 CPU 上。可以通过使用WithDevice包装器来覆盖此行为,该包装器可用于显式指定模块应运行在哪个设备上。- Parameters
模块 (
nn.Sequential) – 使用管道并行化的顺序模块。序列中的每个模块都必须将其所有参数放在一个设备上。序列中的每个模块必须是一个 nn.Module 或nn.Sequential(用于在一个设备上组合多个顺序模块)chunks (int) – 微批次的数量 (默认:
1)checkpoint (str) – 启用检查点的时间,可以是
'always','except_last'或'never'(默认值:'except_last')。'never'完全禁用检查点,'except_last'为除最后一个微批次外的所有微批次启用检查点, 而'always'为所有微批次启用检查点。deferred_batch_norm (bool) – 是否使用延迟
BatchNorm移动统计量(默认:False)。如果设置为True,我们将跨多个微批次跟踪统计信息以更新每个 mini-batch 的运行统计信息。
- Raises
类型错误 – 该模块不是
nn.Sequential。ValueError – 无效参数
- Example::
跨 GPU 0 和 GPU 1 的两个全连接层的流水线。
>>> # Need to initialize RPC framework first. >>> os.environ['MASTER_ADDR'] = 'localhost' >>> os.environ['MASTER_PORT'] = '29500' >>> torch.distributed.rpc.init_rpc('worker', rank=0, world_size=1) >>> >>> # Build pipe. >>> fc1 = nn.Linear(16, 8).cuda(0) >>> fc2 = nn.Linear(8, 4).cuda(1) >>> model = nn.Sequential(fc1, fc2) >>> model = Pipe(model, chunks=8) >>> input = torch.rand(16, 16).cuda(0) >>> output_rref = model(input)
注意
您可以使用
Pipe模型并用torch.nn.parallel.DistributedDataParallel包装它,但前提是Pipe的 checkpoint 参数为'never'。注意
Pipe目前仅支持节点内流水线,但将来会扩展以支持节点间流水线。 forward 函数返回一个RRef, 以便将来可以支持节点间流水线,在这种情况下输出可能位于远程主机上。对于节点内流水线,您可以使用local_value()在本地检索输出。警告
Pipe是实验性的,可能会发生变化。- forward(*inputs)[source]¶
通过管道处理单个输入小批量数据并返回一个
RRef,指向输出结果。Pipe是一个相当透明的模块包装器。它不会修改底层模块的输入和输出签名。但是存在类型限制。输入和输出必须至少包含一个张量。此限制也适用于分区边界。输入序列被送入流水线的第一阶段作为
*inputs。因此,该函数的位置参数应与流水线第一阶段的位置参数匹配。同样的条件适用于流水线某一阶段的输出,这同时也是下一阶段的输入。输入张量根据用于初始化
Pipe的chunks参数分割成多个微批次。假设批次大小是张量的第一个维度,如果批次大小小于chunks,则微批次的数量等于批次大小。仅张量被拆分为多个微批次,非张量输入 在每个微批次中只是按原样复制。对于流水线最后阶段的非张量输出,它们会被聚合为一个
List并返回给用户。例如,如果你有两个微批次 返回整数 5,用户将收到合并后的输出 [5, 5]所有输入张量都必须位于与流水线第一个分区相同的设备上。
如果张量被
NoChunk包装器包装,则该张量不会在微批次之间拆分,并且会像非张量一样直接复制。- Parameters
inputs – 输入的小批量数据
- Returns
RRef到小批量的输出- Raises
TypeError – 输入中至少不包含一个张量
- Return type
RRef
跳跃连接¶
某些模型如 ResNeXt 并不是完全顺序的,并且在层之间具有跳跃连接。如果简单地将其作为管道并行性的一部分来实现,则意味着我们需要将某些层的输出复制通过多个GPU,直到最终到达包含跳跃连接层的GPU。为了避免这种复制开销,我们提供了以下API,在模型的不同层中存储和弹出张量。
- torch.distributed.pipeline.sync.skip.skippable.skippable(stash=(), pop=())[source]¶
定义一个装饰器,使用
nn.Module创建具有跳跃连接的模型。这些带有装饰的模块被称为“可跳过”。即使该模块没有被
Pipe包裹,此功能也能完美运行。每个跳过张量都由其名称进行管理。在操作跳过张量之前, 可跳过的模块必须通过 stash 和/或 pop 参数静态声明跳过张量的名称。具有预先声明名称的跳过张量可以通过
yield stash(name, tensor)进行存储,或者通过tensor = yield pop(name)进行弹出。这是一个包含三个层的示例。名为“1to3”的跳过张量分别在第一层和最后一层被存储和取出:
@skippable(stash=['1to3']) class Layer1(nn.Module): def forward(self, input): yield stash('1to3', input) return f1(input) class Layer2(nn.Module): def forward(self, input): return f2(input) @skippable(pop=['1to3']) class Layer3(nn.Module): def forward(self, input): skip_1to3 = yield pop('1to3') return f3(input) + skip_1to3 model = nn.Sequential(Layer1(), Layer2(), Layer3())
一个可跳过的模块可以存储或弹出多个跳过张量:
@skippable(stash=['alice', 'bob'], pop=['carol']) class StashStashPop(nn.Module): def forward(self, input): yield stash('alice', f_alice(input)) yield stash('bob', f_bob(input)) carol = yield pop('carol') return input + carol
每个跳过张量必须恰好与一个 stash 和 pop 对相关联。当包装模块时,
Pipe会自动检查此限制。您也可以通过verify_skippables()检查该限制,而无需使用Pipe。
- class torch.distributed.pipeline.sync.skip.skippable.stash(name, tensor)[source]¶
保存跳过张量的命令。
def forward(self, input): yield stash('name', input) return f(input)
- Parameters
名称 (str) – 跳过张量的名称
input (torch.Tensor 或 None) – 传递给跳跃连接的张量
- class torch.distributed.pipeline.sync.skip.skippable.pop(name)[source]¶
弹出跳过张量的命令。
def forward(self, input): skip = yield pop('name') return f(input) + skip
- Parameters
名称 (str) – 跳过张量的名称
- Returns
之前以相同名称被另一层存储的跳过张量
- Return type
请提供需要翻译的单词列表。
- torch.distributed.pipeline.sync.skip.skippable.verify_skippables(module)[source]¶
验证底层可跳过模块是否满足完整性。
每个跳过张量必须只包含一对 stash 和 pop。如果有未匹配的一对或多对,将引发带有详细信息的
TypeError。这里有一些失败案例。
verify_skippables()将会报告这些案例的失败情况:# Layer1 stashes "1to3". # Layer3 pops "1to3". nn.Sequential(Layer1(), Layer2()) # └──── ? nn.Sequential(Layer2(), Layer3()) # ? ────┘ nn.Sequential(Layer1(), Layer2(), Layer3(), Layer3()) # └───────────────────┘ ^^^^^^ nn.Sequential(Layer1(), Layer1(), Layer2(), Layer3()) # ^^^^^^ └───────────────────┘
要对多个跳过张量使用相同名称,它们必须通过不同的命名空间进行隔离。请参阅
isolate()。- Raises
TypeError – 一个或多个 stash 和 pop 的配对不匹配。
致谢¶
管道并行的实现基于 fairscale 的管道实现 和 torchgpipe。我们想感谢两个团队为将管道 并行引入 PyTorch 所做出的贡献和指导。